Better RAG 1: Basics
Large Language Models have proven themselves to be wonderful few-shot learners, almost general-purpose intelligences that can learn and execute new tasks, process complex information and serve as digital assistants. However, their limited input/output window (known as context) has been the biggest hurdle in making them truly intelligent. Beyond the trillions of words used in pretraining - an expensive and time-consuming process - we are often limited to thousands of words (sometimes less than a few pages of writing) in which we can provide new information and instructions, to generate an output.
If we can connect the corpus of human data with the increasing but limited contexts of LLMs, we can create systems that can learn and adapt on the fly - the same way humans can. We can build agents with persistent long-term memories, that can remember and make use of our organizational and personal data.
A lot of subproblems exist in this space, but one of the simplest is that of Q&A: Given a question (from a user or an AI), can we combine LLMs with data they've never seen before to provide good answers?
Retrieval-augmented-generation has become the simple catch-all for a lot of work in this direction. Most systems today utilize a simple pipeline: import information, embed the results (we'll explain embeddings as we go on), retrieve relevant chunks to the question, import these chunks to the limited context of a model, and ask it to answer the question. Seems pretty simple.
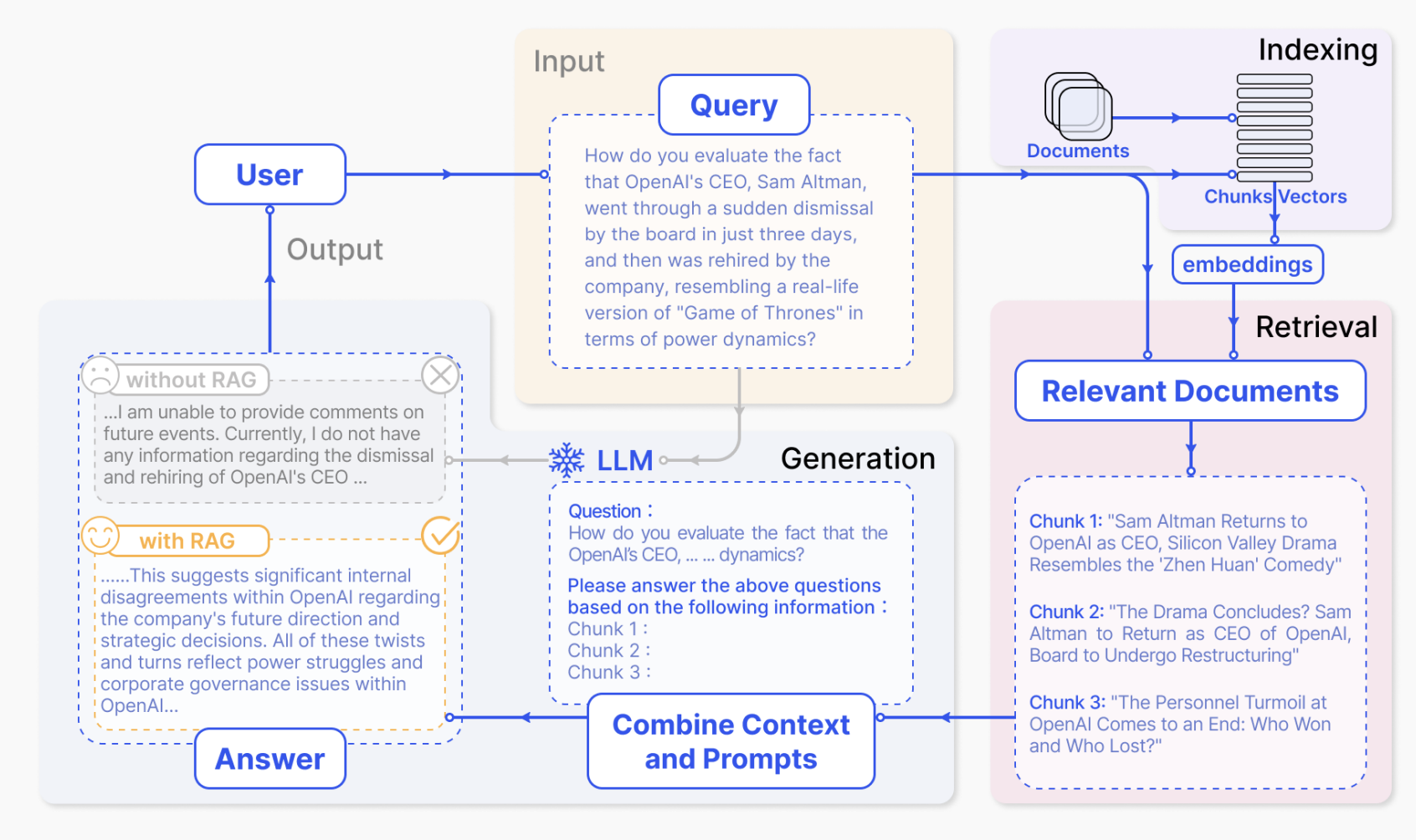
However, things fall apart pretty quickly in practice. Retrieving the relevant parts of a very large dataset using only the information contained in a question is a pretty tall order. Depending on how complex the question is, you might need to fetch information from multiple different parts of a dataset and use references and relationships in the data to find more information that can help you arrive at an answer.
Furthermore, you're always limited in the amount of information you can fetch. Even with expanding context sizes, reasoning and intelligence in models reduces the more information you inject into their input windows. Combined with increasing cost, compute and memory, retrieving higher qualities and lower quantities of information will remain a concern for the foreseeable future. This is also the reason why the modern RAG landscape can seem scary and complex - all of them represent different attempts to solve the same problems.
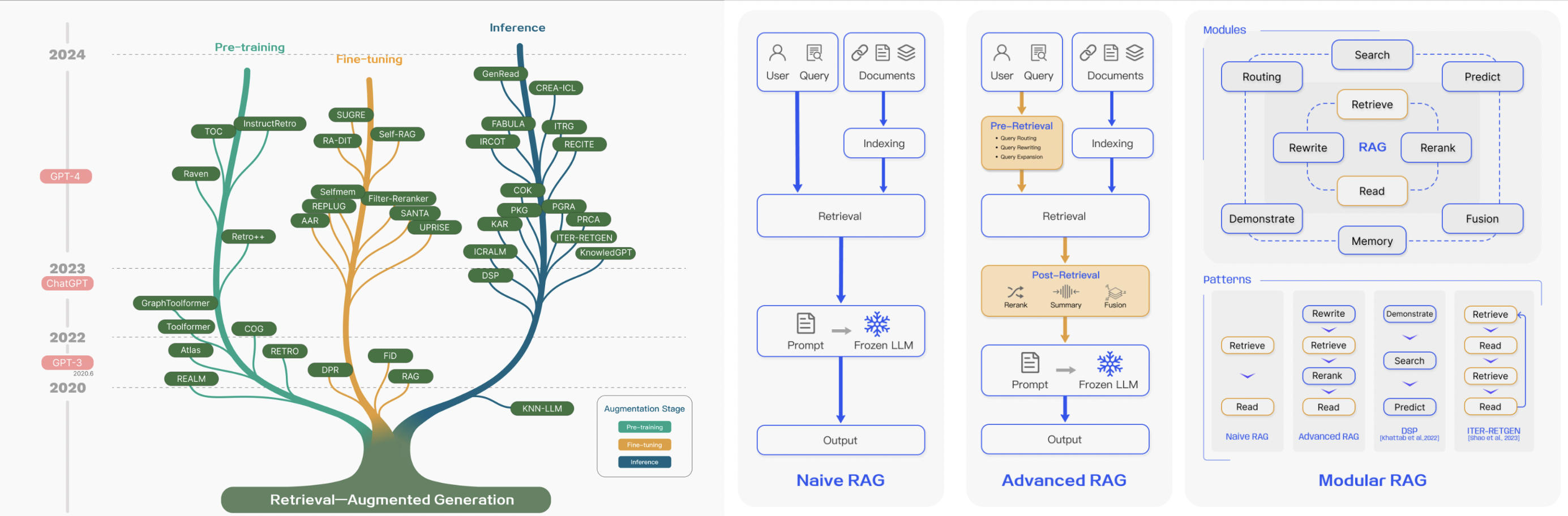
The illustrations above are taken from the wonderful paper from Gao Et al covering the current landscape of RAG systems and techniques. It's a more technical overview of what exists - and covers a lot more things that are out of scope for this series.
§Better methods
In this three-part series, we'll go over ways to solve this problem. We'll start at the final step - generation - and walk all the way back to the source information, and look at improving each part.
This part will be an explanation of how RAG systems work today, the complexities to consider, and the common problems we want to solve. Feel free to skip this one! The other parts will presume a working knowledge of embeddings, retrieval systems, LLM-based processing and so on.
Part 2 will cover cyclic generation ('walking') or ways to give AI models the ability to request new information, discover long-range relationships in the information and combine them for better results. If you're familiar with WalkingRAG, this part will cover the eponymous concept and show you how to do it yourself.
Part 3 will go over transformations on the query and source data to improve retrieval performance.
Let's start with the basics.
§Retrieval Systems
The first problem we encounter in the question-answer scenario is that of search. It has long been theorized that the problem of intelligence is that of search ([1] [2] [3]) - that if you can organize and retrieve information about the world relevant to any problem, you've solved 90% of what makes up an intelligent system.
This is something we've tried to solve many times before:
- BM25 uses keywords from the query to estimate similarity and relevance to source documents - something we've used for 30-plus years.
- PageRank uses references between pages as a way to estimate similarity and rank information based on relevance to other pieces of information.
- TFIDF looks at the frequency of words inside a source document to estimate relevance.
In all cases, we're trying to use information from the query to find relevant parts of source documents. Our current AI summer has given us a few more tools:
- LLM Pretraining is one of the best methods we have of truly indexing large amounts of information (trillions of words) into a small network. If you've ever used ChatGPT for research, you've used it to search the pertaining corpus. Unfortunately, this is prohibitively expensive - training runs are finicky, and it's hard to induct new information without doing a completely new training run.
- In-context learning uses the context window of a language model (the input space at runtime) to inject information into the knowledge of a model. However, this space is highly limited - the largest useful contexts are still thousands of times smaller than pretraining datasets (or a thousand times smaller than the amount of email a 100-person company generates in a year). In-context learning is also very expensive - the attention mechanism inside LLMs that gives them powerful learning capabilities makes token windows expand exponentially in cost.
However, one of the most valuable things to come out of the last few years of AI development has been embeddings and embedding models, which have now embedded themselves into retrieval pipelines everywhere. (Perhaps too valuable - part 3 will cover the problems we create when we embed too early, and too often.)
Here's the technical definition of an embedding from Google:
An embedding is a relatively low-dimensional space into which you can translate high-dimensional vectors. Embeddings make it easier to do machine learning on large inputs like sparse vectors representing words. Ideally, an embedding captures some of the semantics of the input by placing semantically similar inputs close together in the embedding space.
I admit I barely understand that sentence on my best days. Let's try a simpler explanation, trading in accuracy for better functional understanding.
An embedding can be seen as a brain slice of an ML model that understands language, at the point in time it hears something. Imagine someone taking a snapshot of your brain when you hear a sentence. You find out which neurons and parts of your brain activate, as you try to understand it.
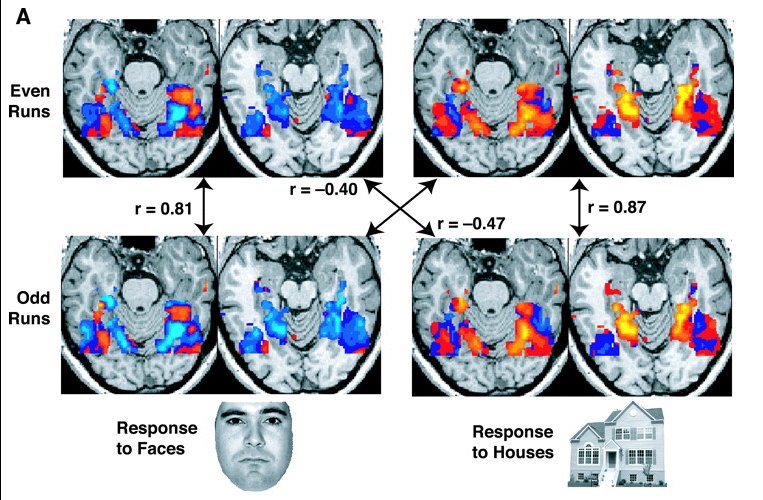
On its own, this is pretty useless. However, similar to our research into brains, this becomes extremely useful when you start comparing brain slices with input sentences. Similar sentences - with similar concepts - start activating the same parts of the brain, even if the actual sentences are different. We can then use similarity here as a higher-level proxy for sentence similarity.

This is exactly what we see when we look at embeddings. Sentences with similar concepts cluster together, even if none of the text looks the same. Here's an example - embeddings of Tiktok posts, clustered by topic.
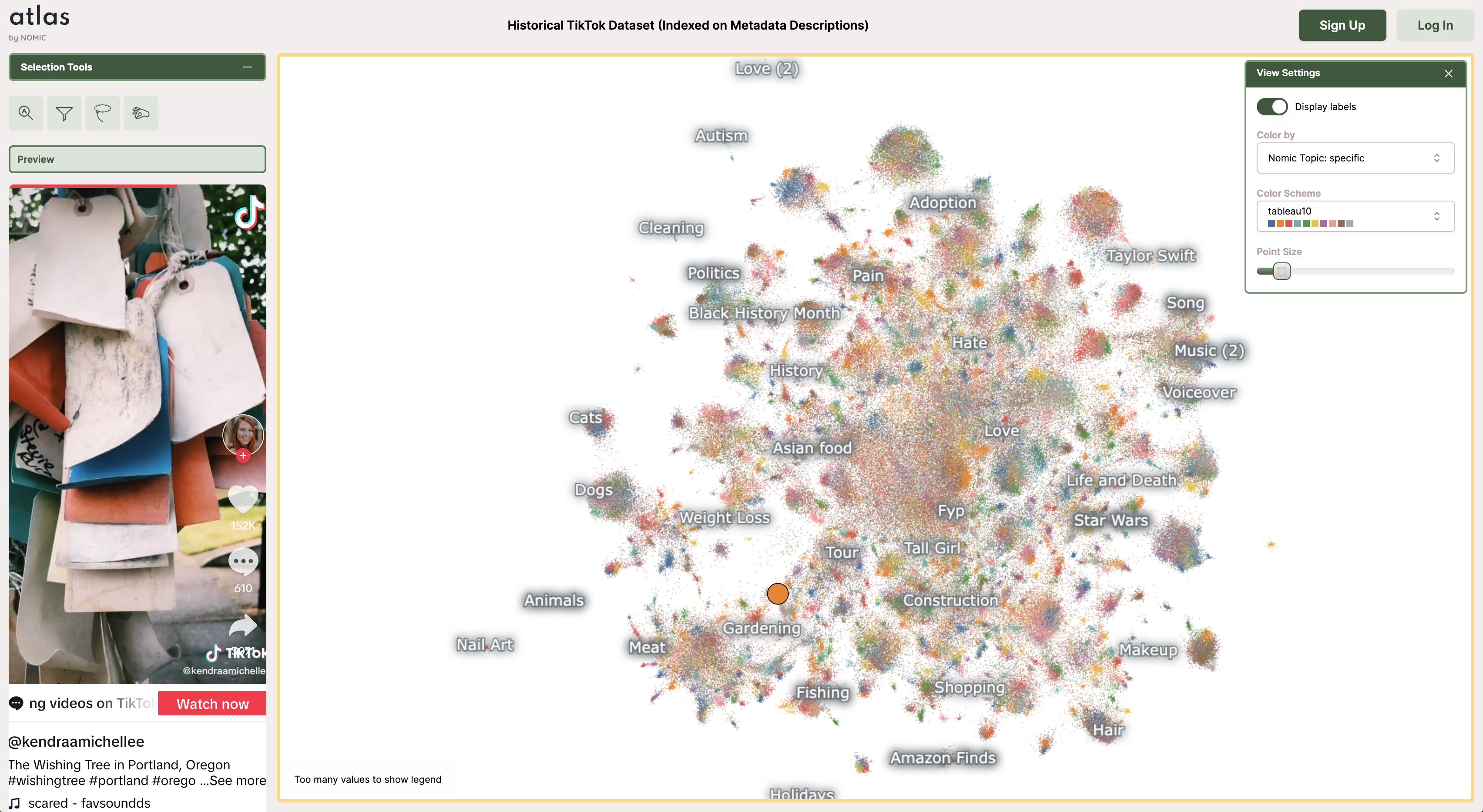
This is also why you can't mix and match embeddings from different models. Because each brain is different, similarity in embeddings (or brain slices) only makes sense for the same brain - differently trained models store information differently. An embedding from OpenAI cannot be directly compared to an embedding from Nomic, the same way brain activations for me are not the same for you, even for the same sentences.
Retrievers like BERT and ColBERT are outside the scope of this article. They represent a different class of models trained specifically for retrieval, that can be highly effective in certain cases. This thread from Omar is a good place to start if you're interested.
§Problems
On the one hand, we have traditional methods like BM25 and TFIDF which rely on text-similarity - a lot less intelligent than ML-based retrieval and more brittle to changes in spelling, but far more controllable and inspectable.
On the other, we have embedding-based retrieval methods, which can be useful for semantic similarity, but have a black-box problem. Embeddings are effectively inscrutable brain slices, and while some amount of math can help us transform embeddings, we're only beginning to scratch the surface of understanding what these encodings really mean. They're amazing when they work, but hard to fix when they don't - and they're usually more expensive than traditional search.
We also have in-context retrieval and learning - which is our highest quality, most expensive method, even if you can fit everything into a context window.
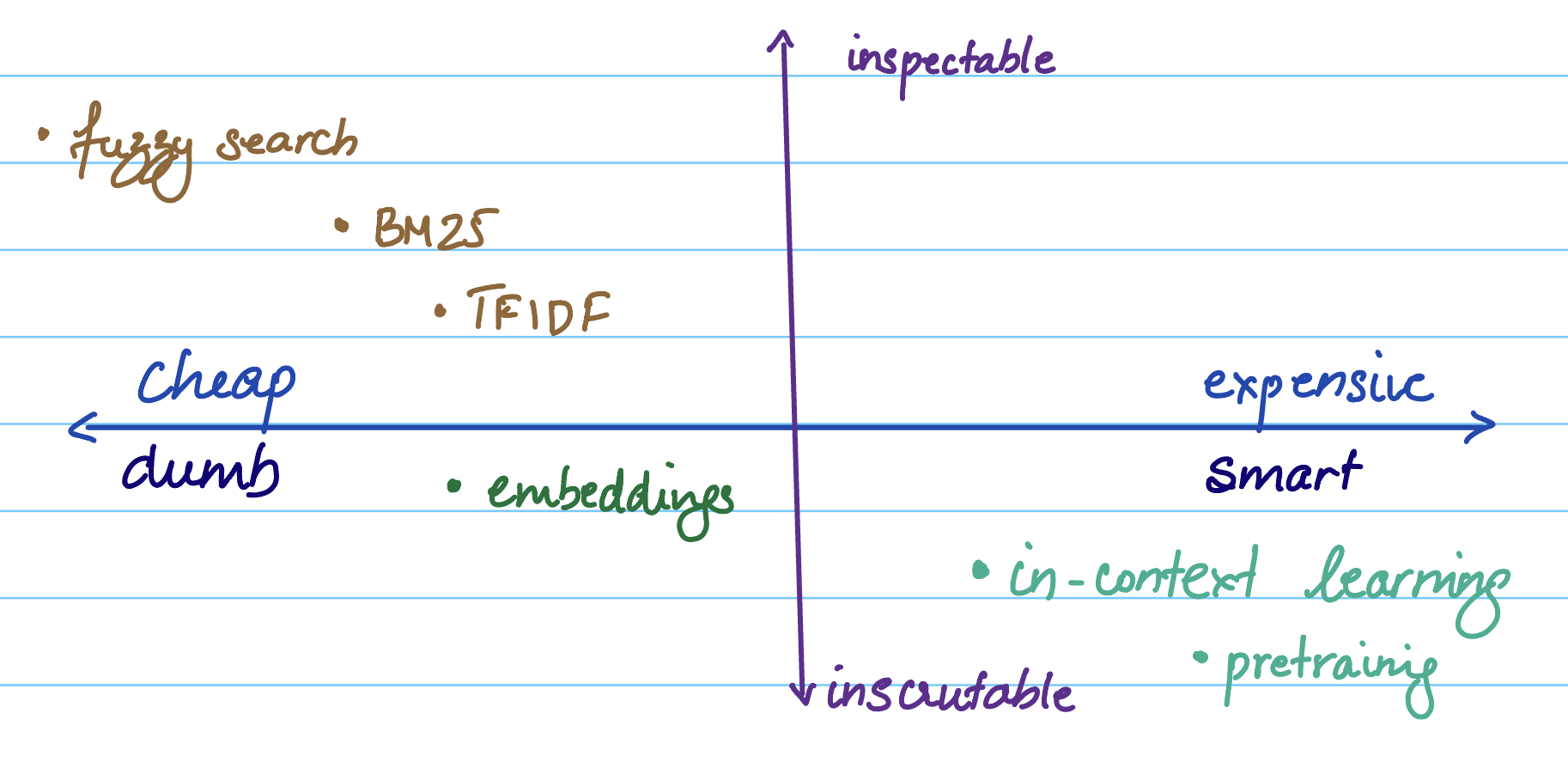
Most RAG systems should therefore eventually end up with a similar architecture: Use cheaper methods to cut down the search space, and add increasingly expensive and smarter methods further down the pipeline to find your way to the answer.
However, there are two additional dimensions of complexity that are often overlooked.
§Question Complexity
This is similar to the problem of prompt complexity - something I've covered before. Queries can vary widely in how complex they are - both in what they're asking for and the kind of retrieval that needs to happen:
- Single Fact Retrieval questions can be some of the simplest. This is when the question is asking for a single piece of information that is either present or absent in your data, and you're successful if you retrieve the right piece. 'What is one embedding model discussed in this article?' requires your system to find a specific piece of information that is in this article.
- One level up we can have Multi-fact retrieval. 'What are the key types of retrievers being discussed?' requires an exhaustive answer of all the major types, where failure to retrieve any one of them can be an issue.
- Further up we have Discontiguous multi-fact retrieval, where the information is not continuously present in the same part of the dataset. 'What are the descriptions of RAG systems used in the article?' would be a good example.
- Next we have Simple Analysis questions. 'What are the main parts of this series, and how do they connect?' requires an understanding of one specific section of the document.
- Complex Analysis questions can be harder, and require extended information from multiple parts of a dataset. In our case, this could be something like 'How do embeddings compare to BM25, according to the author?'
- Finally we have Research level questions. These can be as complex as 'Why is ColBERT outside the scope of this article?' or 'What are the key arguments and positions made in this piece?'. On a larger dataset (like revenue projections), this can be something like 'How have the 2021 undertakings fared in generating new avenues for business?'
Not understanding question complexity can be the Achilles heel for modern RAG systems. If there is an inherent mismatch between user expectations and systems design, the specific tradeoffs made in a system (speed vs cost, smarter vs safer, etc) can completely fail the first interaction between user and machine.
On the other hand, having a good estimate of the expected classes of questions can make a big difference when building a system from scratch. For example, if you expect complexity to remain under level 4, early transformations of the input data to pre-extract facts can significantly speed up search - and make it easy to identify which benchmarks to use in your evaluation.
§Steering and Inspectability
What is also usually neglected is the problem of steering. Things are great when they work, but the difference between demo and production is what tools you have at your disposal when they don't.
One of the biggest benefits of LLMs over other ML solutions has been their ability to provide intermediates - outputs that can be modified, controlled or inspected to change behavior in predictable ways. We'll cover this more in subsequent parts, but intermediates (like chains of reasoning, labels, etc) can be crucial in making large-scale systems less black-box-y.
Throughout this series we'll argue for methods that improve retrieval performance, make our systems easier to inspect and control, and how we can handle increasing question complexity. See you at the next one!
§An interactive demo
Here's a live comparison between in-context learning and a RAG-based approach.
This Huggingface Assistant uses this article as part of the context to Mistral-7b, a relatively tiny model with 7 billion parameters.
This GPT uses the same article, but makes use of embeddings and retrieval to answer the same questions, albeit with a model 50 times or more the size of Mistral-7b.
Provided you didn't skip to the end, you should now be able to ask questions to both that illustrate the key differences.

Not a newsletter





