Better RAG 3: The text is your friend
This is part 3 of a series on Retrieval Augmented Research, or how to build better RAG systems to answer complex questions. Part 1 covers the basics and key concerns when building RAG systems, and Part 2 covers multi-turn retrieval, or 'walking'.
In this part, we'll go over transformations that can be applied to your source data and the question, to improve retrieval.
A lot of RAG pipelines embody the paths their creators took to discovering embeddings - including mine - and a lot of us fall into the same trap.
First, you find embeddings and leave the world of fuzzy search behind. Maybe you've heard of BM25, or perhaps Elastic or Postgres were the closest you had - but embeddings are great! True semantic search for the first time! Much like any addictive new tool you start to use and then overuse it.
Before you know it you've embedded everything you can find, and you're retrieving too much. It works sometimes, and other times nothing works. Everything you search for has thousands of matches, and no amount of context will fit everything you can retrieve. Increasing flat embeddings with no real organization lands you back in fuzzy search territory, just with smarter models.
You stop and look around - you have a lot of embeddings (some would say too many - I'm one of those people). The logical next step might be a reranker, or some kind of bias matrix to structure embeddings and search results.
These are not bad things per se - rerankers and embedding transformations are incredibly useful last steps in your retrieval pipeline. They're just in the wrong place, in the wrong order.
What if we started at the beginning?
§Plaintext is your friend
I say text, but this applies to both multi-modal retrieval (images, video) and plaintext.
The source corpus - this can be your document store, images, PDFs, etc - is the most amount of useful information you'll have in your pipeline. Once we start embedding things, we lose information - often in uncontrollable ways.
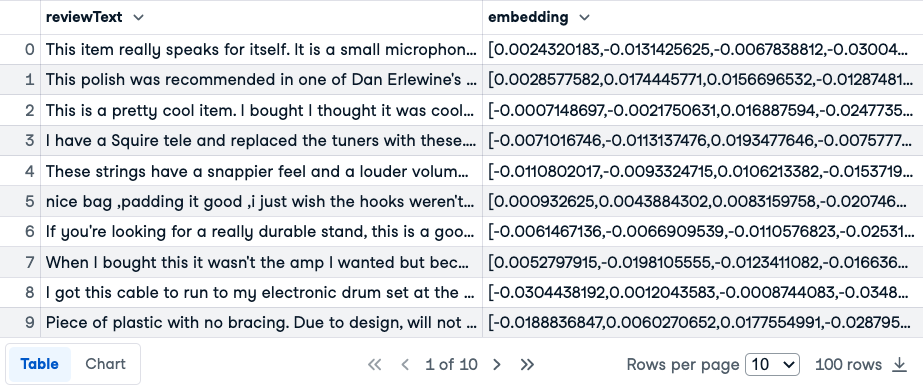
Which column do you think has more useful information, especially with LLMs as a tool?
Once we begin chunking/embedding/applying matrices, we lose control and information at each stage. The first stage of any processing pipeline should be trying to transform and uncover information from your source document, with two primary goals.
§Metadata Extraction
The first is to pull out metadata that can help cut down the search space as much as possible before we get to semantic search. Even a single binary label applied to your chunks can halve your search, memory and computational complexity while doubling retrieval speed (and hopefully accuracy).
Here's a GPT demonstrating naive structure retrieval by building a real-time typespec and filling it with information.
In fact, here's a Huggingface Assistant running on Mixtral, a much smaller model - where you can inspect and edit the prompt!
Let's throw in our first article from the series and see what we get:
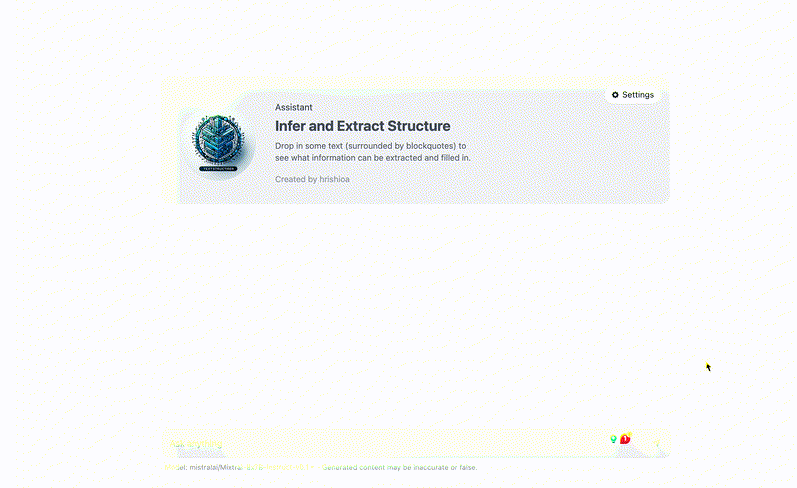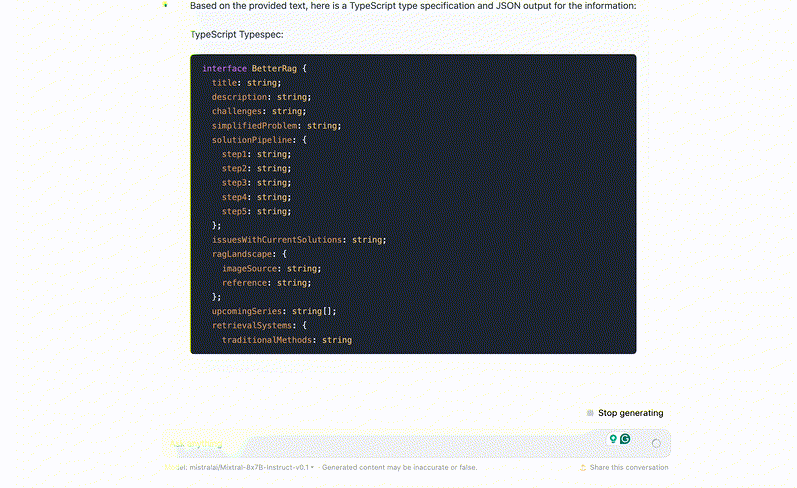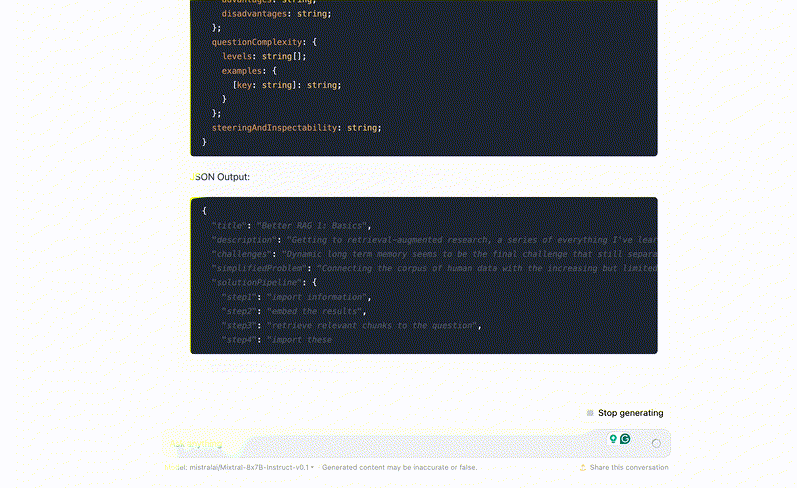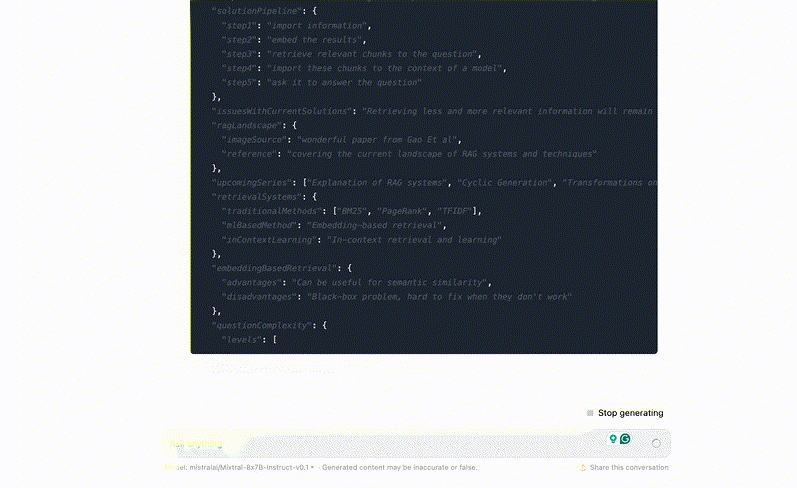
All we're doing here is asking the model to create a dynamic typespec and fill it in. Even with this naive approach, we get a lot more we can work with:
- the keywords can be used for simple classification.
- implied structure can be correlated to query transformations.
- summarised titles and summaries can serve as better embedding surface area to match your question.
You also get steerability here - structured search can be modified, adjusted and fixed far easier than mucking about in n-dimensional embedding space.
§Reducing the distance between questions and answers
The second goal is to reduce the distance between your query and the relevant information inside your data. You might get lucky sometimes - your questions might come from the same authors as your documents, and they might be looking for simple, single fact retrieval.
In most cases, you'll find that your questions look and sound nothing like the relevant answers. Transformations on both sides can help bring them closer together.
Always remember that embeddings look for simple meanings and relationships. SemanticFinder is a wonderful place to test the limits of embeddings. Smaller embedding models can be a great place to learn and firm up intuitions about semantic search, by pointing out issues early. Here's a question to try: "How many people lived there at the end?"
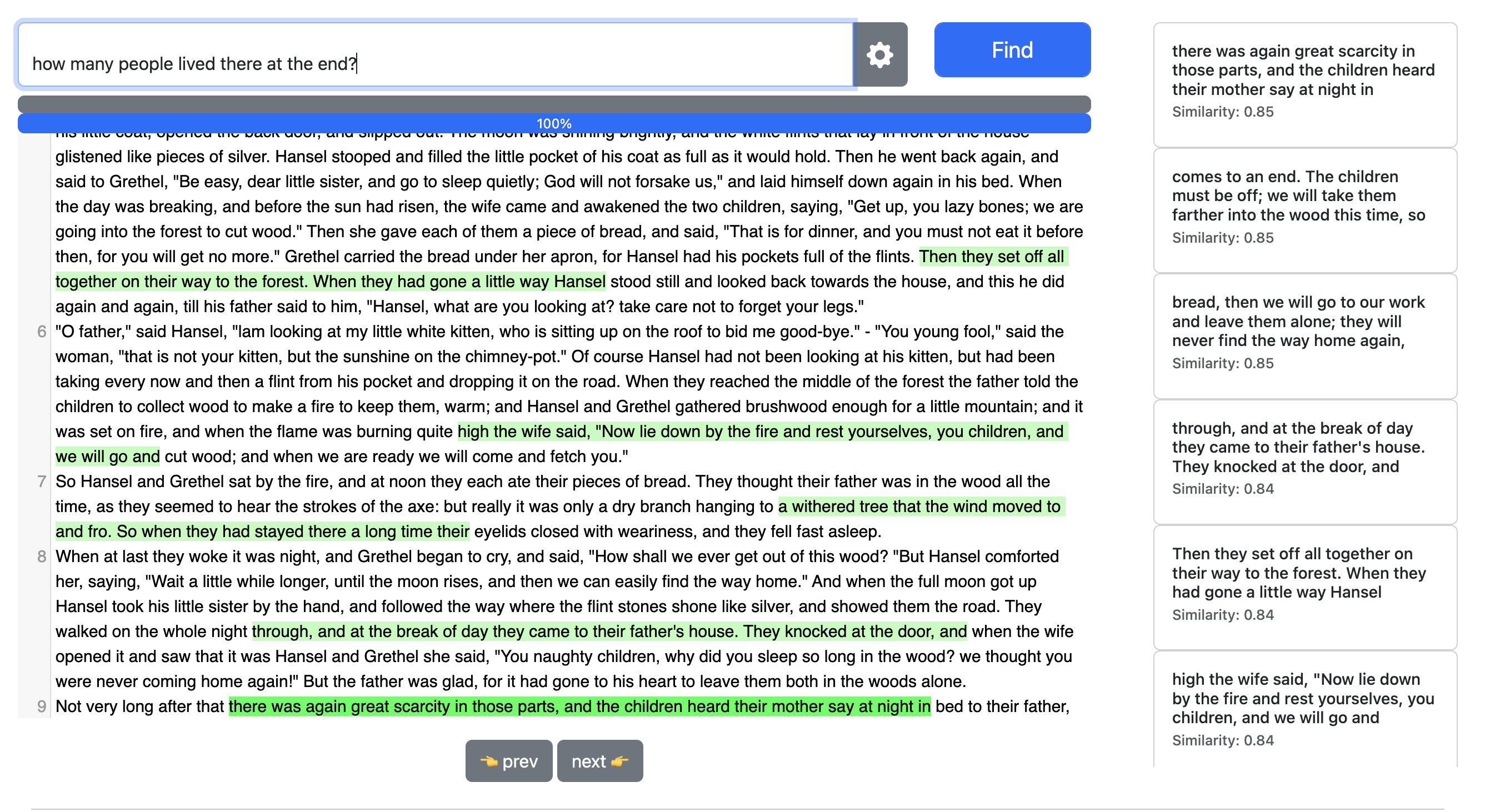
In the ideal case, you should be transforming both your question and your corpus so they move closer to each other.

This isn't a new concept - one of the most successful RAG techniques has been HyDE - Hypothetical Document Embeddings, which tries to generate potential (fake) answers to the question, in the hopes that the embeddings of these answers match real answers more closely.
You can also do the inverse. In WalkingRAG, one additional step we perform at ingest is to generate hypothetical questions that are answered by each section of a document. The embeddings of these questions are far closer to the actual user question than the source data - it's also a helpful multi-modal step, to generate text questions from purely visual information. More on that another time, but here's an example:
Here is another example GPT to demonstrate some transformations. You can try your own documents, and potentially even plot the embeddings of the transformations to see how much closer they are to each other.
Let's try it out:
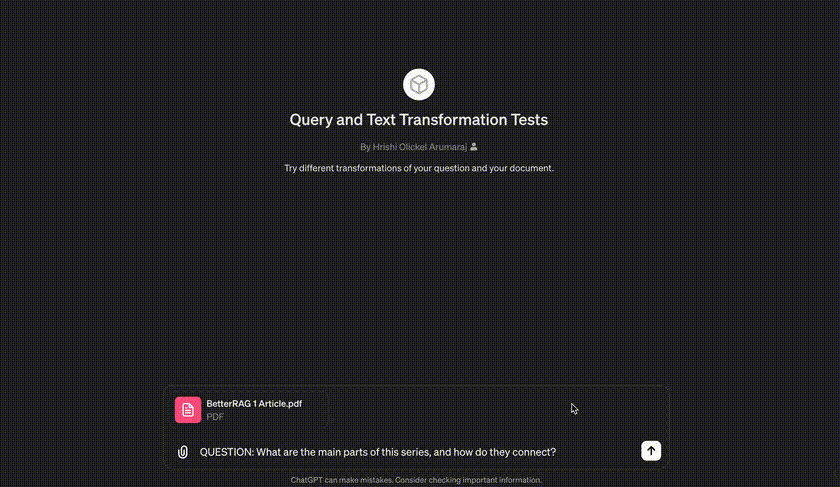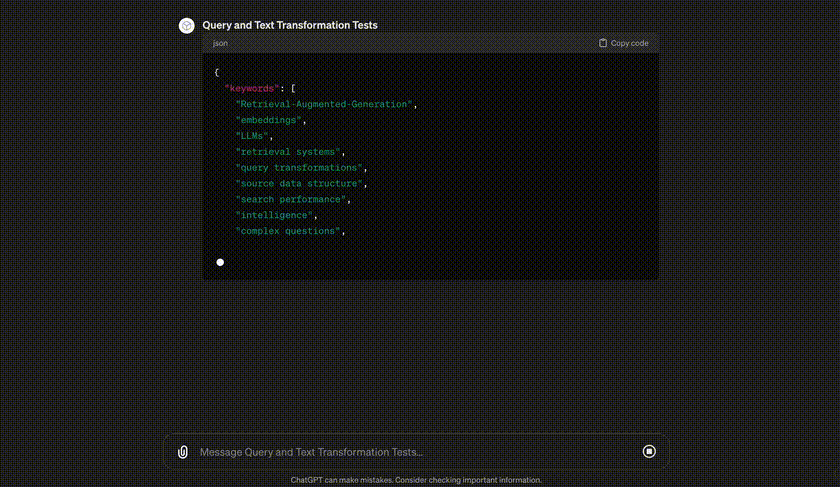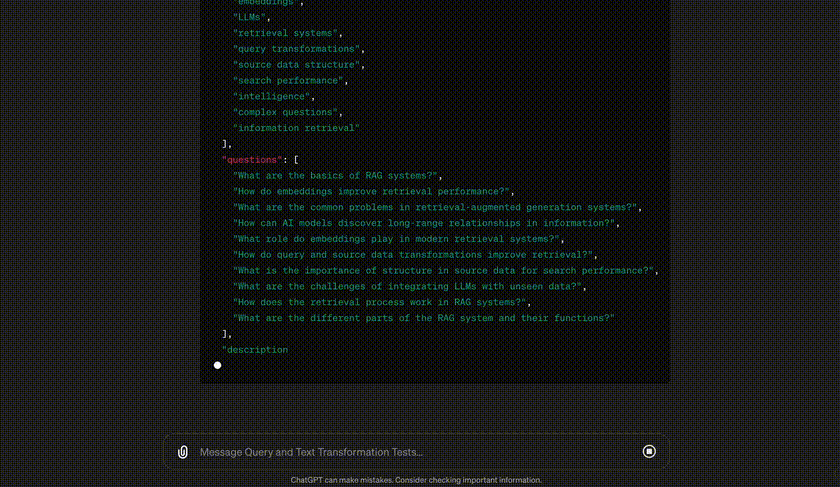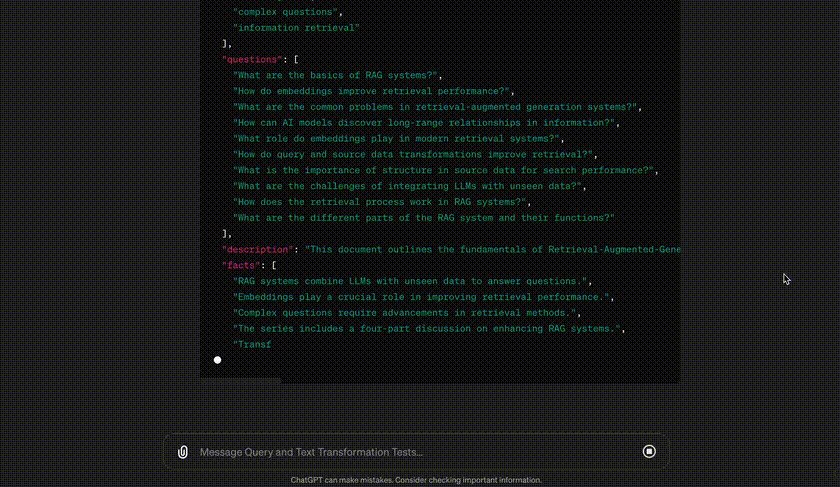
At the beginning of the response, we can see the hypothetical subquestions extracted from our simple question. Answering (or embedding) each of these can find disparate information buried in our dataset. On the other hand, we can see extracted facts and summaries that are more relevant to the question being asked.
§A lot more to do
Once you start using LLMs as transformation tools ahead of other steps, there starts to be a lot more you can do. For example, you can:
-
Generate reasoning steps toward answering the question (without any chunks or documents in the context). The number of steps generated can be a useful proxy for judging question complexity, and the steps themselves can be useful retrievers to find relevant chunks.
-
Annotate your document for ambiguity. For each chunk, generate potential web searches to retrieve more information. Even if you never run these searches, they become useful pointers to information that the model might be missing. You can also run the most common searches across the whole document and add the results to your dataset as supplemental information.
-
RAPTOR and other methods point to recursive summarisation as a useful tool in boosting cross-dataset answering. Long-range summaries can connect information across wide-ranging chunks, and help in answering complex questions.
§Conclusion
I'm hoping this can be an open-ended series. There are a lot more concepts yet to be covered - from structured extraction, guided outputs, and using LLM contexts over a million tokens effectively. As language models and our understanding of embeddings evolve, we'll find new ways to improve knowledge organization and retrieval.
In the meantime, here are some useful rules of thumb that have helped me:
- Keeping things simple can be very helpful, especially from a model perspective. It can be attractive to use multiple model architectures and complex prompt optimization pipelines - and often they can net you an additional percent or two in accuracy. However, keep an eye on the tradeoff you might be making in terms of complexity and maintainability. The more black-box ML that you add to a pipeline, the harder it becomes to upgrade, maintain and control.
- When building a new system, start from the query in. Understand the class of questions your system will be expected to answer, and line up expectations with customers, users and yourself. It can be tempting to build general-purpose - modern AI systems feel like they're 'almost there' in being able to tackle anything and everything. However, a lack of definition of the problem space can often mean that you're unaware of the tradeoffs being made.
- Separate the work being done at query time from what you do on ingest. In an ideal system, you should be doing things in both places - and being aware of the fact that your information set changes between ingest and query can make a big difference.
I hope this has been helpful. If you have any questions or comments, feel free to reach out to me on Twitter.

Not a newsletter





