Object-Oriented Large Language Modelling
The biggest problem facing language models (like GPT) today, would
Large language models like GPT-3 and GPT-4 have jumped us forward in AI in a way that we are only beginning to comprehend. Getting a machine to understand human language has provided us with emergent capabilities for reasoning and general intelligence that we were trying to achieve through games, with Deepblue and AlphaGo.
Whether we get to a general intelligence that can improve itself or not, LLMs today are hugely promising for all of human civilization because of the pervasiveness of language. It's what we use to tell each other stories, and to keep our species together. We use it internally to think, and it's how we preserve our collective consciousness.
A lot of work is being done in turning these models into Agents like BabyAGI and AutoGPT, but the achilles heel of today's models is reliability. These models are tuned to be interesting, and that makes them not very reliable. They fail unpredictably, and in complex ways the make it hard to fix. This is slowly becoming the general consensus.
Remember the old problem with complex code?

That's what we seem to have returned to. At Greywing, we have been releasing products aimed at complete communication automation - no humans in the loop - and that makes reliability our primary focus, even above functionality. Nothing less than 100%.
Object-oriented LLMing - as we're come to call it - is the practice we've begun to follow that shows the most promise. It's helped us mitigate problems of rising prompt complexity, state management, and hallucinations as we push faster releases.
The solution is to use strongly defined object-based interfaces (through criticism and coercion) between multiple agents, and to build generalizable frameworks that make connecting agents to each other trivial.
Is this LangChain? Yes and no. Harrison's amazing library is one that we haven't used yet, for the simple reason that we wanted to learn the nuts and bolts of engineering these systems as we venture into uncharted waters. However, Langchain is a strong recommendation from me if you're starting out with some of the techniques outlined here.
§The problems of talking to a machine
§Problem 1: reliability
LLMs today are like the best video games you've ever played - easy to pick up, hard to master. This explains their popularity, as well as the surprisingly small number of products that make it to market. Anyone can start writing incredibly useful prompts for zero-shot problem solving, but writing prompts that work every time is very, very hard.
Reliability also becomes hugely important as you go up in the number of messages (or rounds) exchanged without human intervention. Much like drift in dead reckoning, errors tend to amplify themselves into larger and larger hallucinations.
§Problem 2: I/O
Input and output are complicated with large language models. The reason they sound interesting to us is because they are trained (even with zero temperature) to phrase things differently, to react intelligently and not in a deterministic fashion - much like the humans that captivate us.
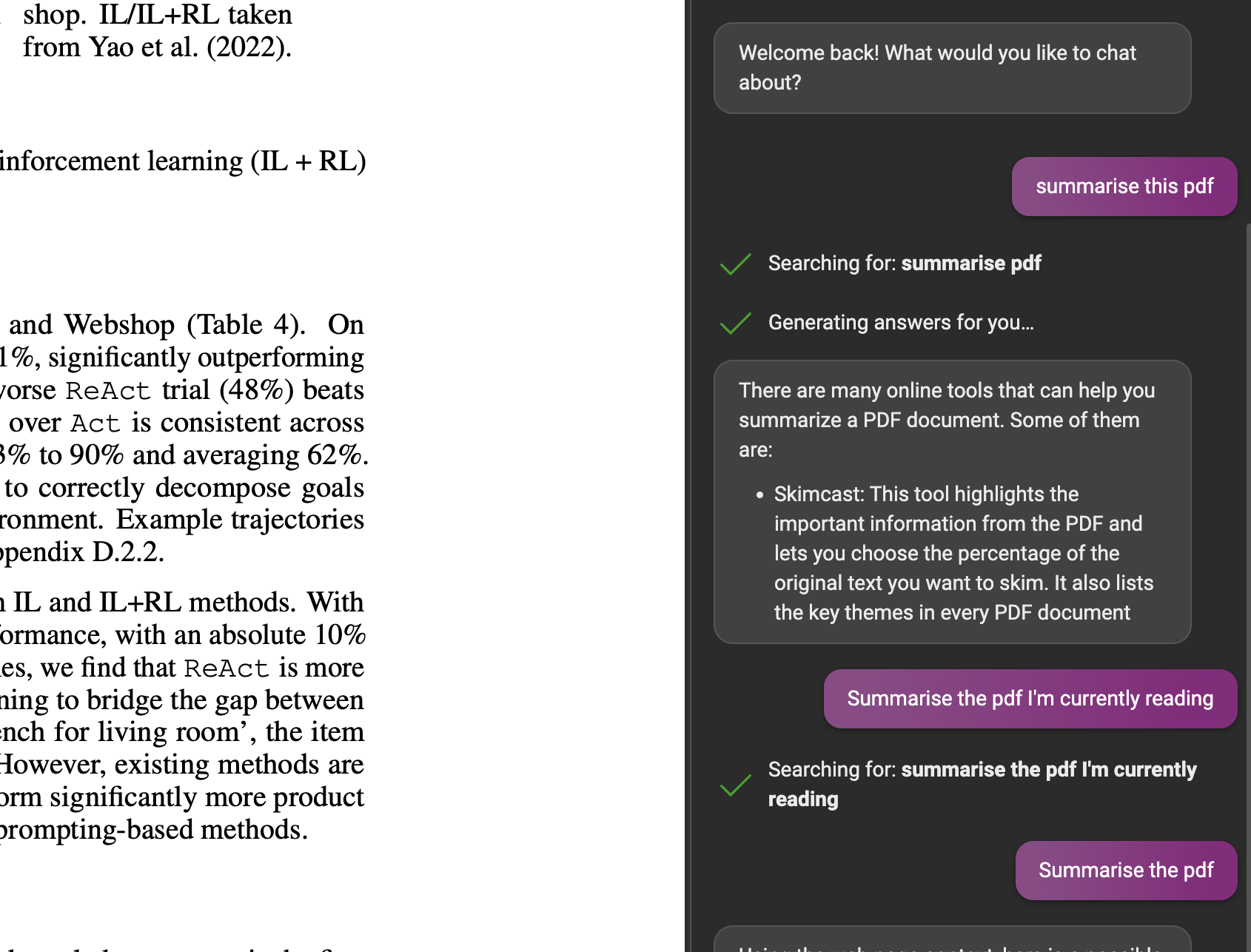
This is hell for the automated systems that need to feed them data and pull out actions. Knowing when to intervene (and with what) is still an open problem - ask Bing, when I try to summarise a pdf:
Creating end-effectors that can extract actions and execute them on the world is also an open problem - but the Agent-based tools I mentioned above are making major progress on this front.
§Problem 3: Prompt complexity
The biggest driver of both of these problems is prompt complexity. The more complex the prompt, the harder it is to make it reliable, or to have it withstand the additional complexity of managing input/output.
Think of the capacity of a model to execute a prompt as a budget. This budget is on a tradeoff with reliability - the less you use, the better your output reliability will be. This is a shared budget between three things - task complexity, inference complexity, and ancillary functions. If you want the same reliability while increasing one, you need to decrease another.
Task complexity is the how difficult the actual task is. If you give it a hard logic puzzle (or ten sequence tasks in a row), task complexity dominates. If you have a simple task like finding the synonyms for a word, the low task complexity leaves room for other things. The number of tasks in a prompt (especially sequential prompts) also confuse the system, primarily due to how Attention is executed inside the model. Finding the most important parts of a sentence for each prediction becomes harder when multiple segments of a prompt are trying to influence the output.
The second is inference complexity (thank you Julian for the term). LLMs are similar to humans in that they can infer what you mean even if you don't say all of it. Inference complexity is often inversely proportional to the amount of definition (or facts) you add to help this inference. Here's an example that has high inference complexity:
Translate this idiom from english to french: <idiom>
Here, the language model has to work overtime to understand idioms in both languages, and make sense of the target of translation. The best way to lower this is to provide guidelines like so:
Facts:
Idioms are sayings or colloquialisms in a language.
Good translations of idioms convert the cultural context of an idiom between the languages, instead of literal translations.
Using the facts provided, translate this idiom from English to French: <idiom>
We made a longer prompt, but it was one that was easier to understand. A lower inference budget will leave room for harder tasks or more processing.
The third are the ancillary functions you want to the prompt to perform. This could be giving you structured output, taking previous contexts into consideration, or other smaller things you need to make the output useful. These also factor into the overall budget, and you'll find simpler is often better.
The solution is deceptively simple to grasp, but hard to execute.
§Write smaller prompts with well-defined interfaces
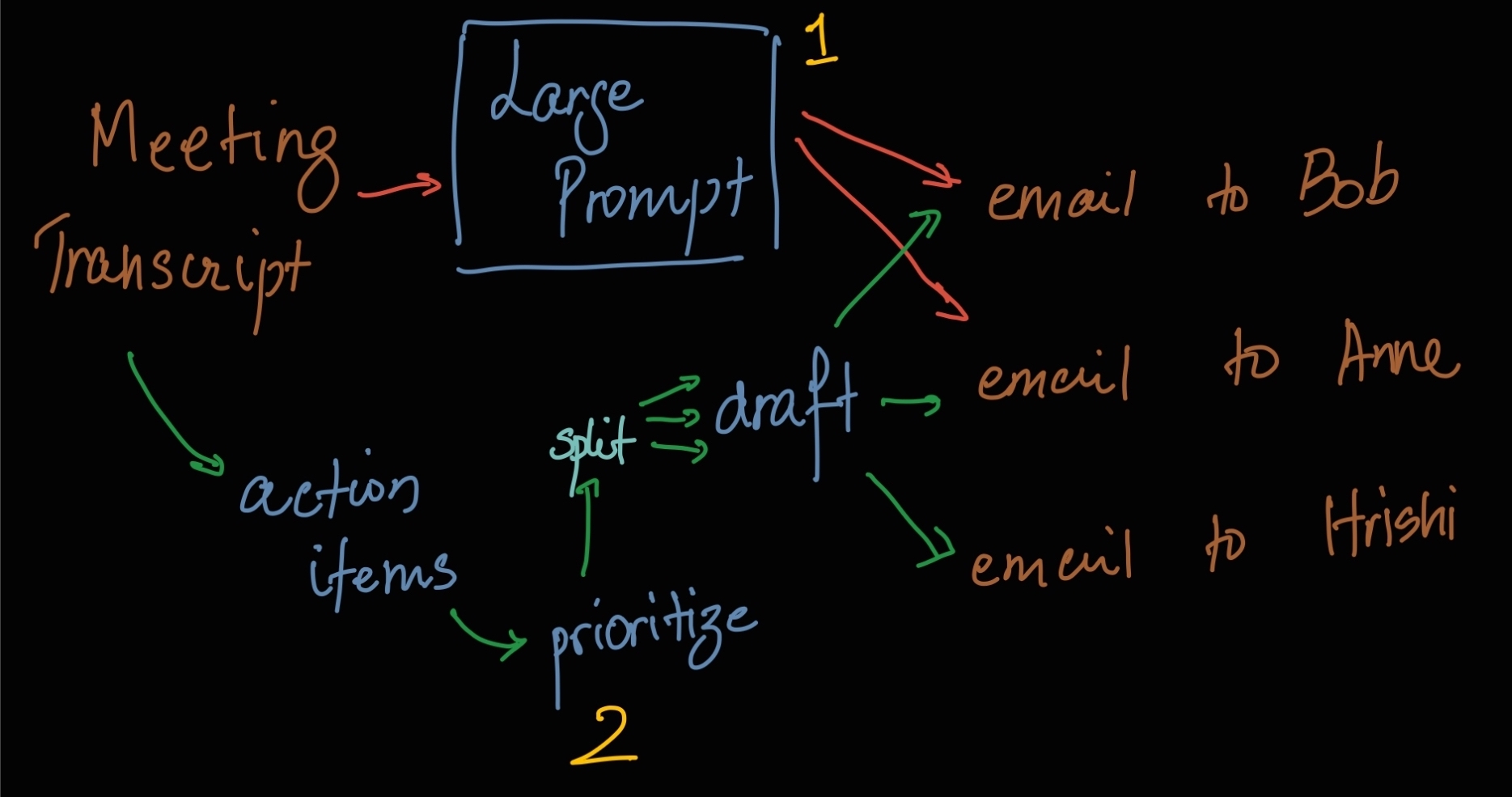
If we can live with the budget of defining thin, easy to define interfaces into our prompts (I'll explain how later down), it becomes easier to write smaller prompts. A deceptively complex prompt, like
For all the participants in this meeting, break down action items, prioritize according to their importance and generate emails to inform them.
can become
List all the action items in this meeting labelled by who they are for in the format <Person>:<Action Item>
Example:
John Hearst:Clean the rain gutters
Followed by structured data coercion and injecting any additional knowledge, then
Use the context to provide a priority number (1 to 10) for each item in the list.
Context (Meeting):<>
Items:<>
And finally
For this set of items, write a formal, energetic, short email listing to the provided person.
Action Items:<>
Person:<>
A much more complex prompt can become smaller tasks, with better interfaces to test and fix for reliable operation.
Implementing the principles of OOP (and stretching to fit), we have the following principles at work here:
-
Abstracting the tasks into email drafting and prioritization make them easier to plug into other parts of your system later.
-
Inheritance can be implemented well tested agents that are extended by modifying provided context and wrapping the output with a criticizing LLM.
-
Encapsulating the models in well defined boundaries (with well-typed specs) makes them easy to plug into each other, or to automated systems.
Finally, here is an example. This is the architecture of the SeaGPT system we use in maritime to automate parts of users' workflow:
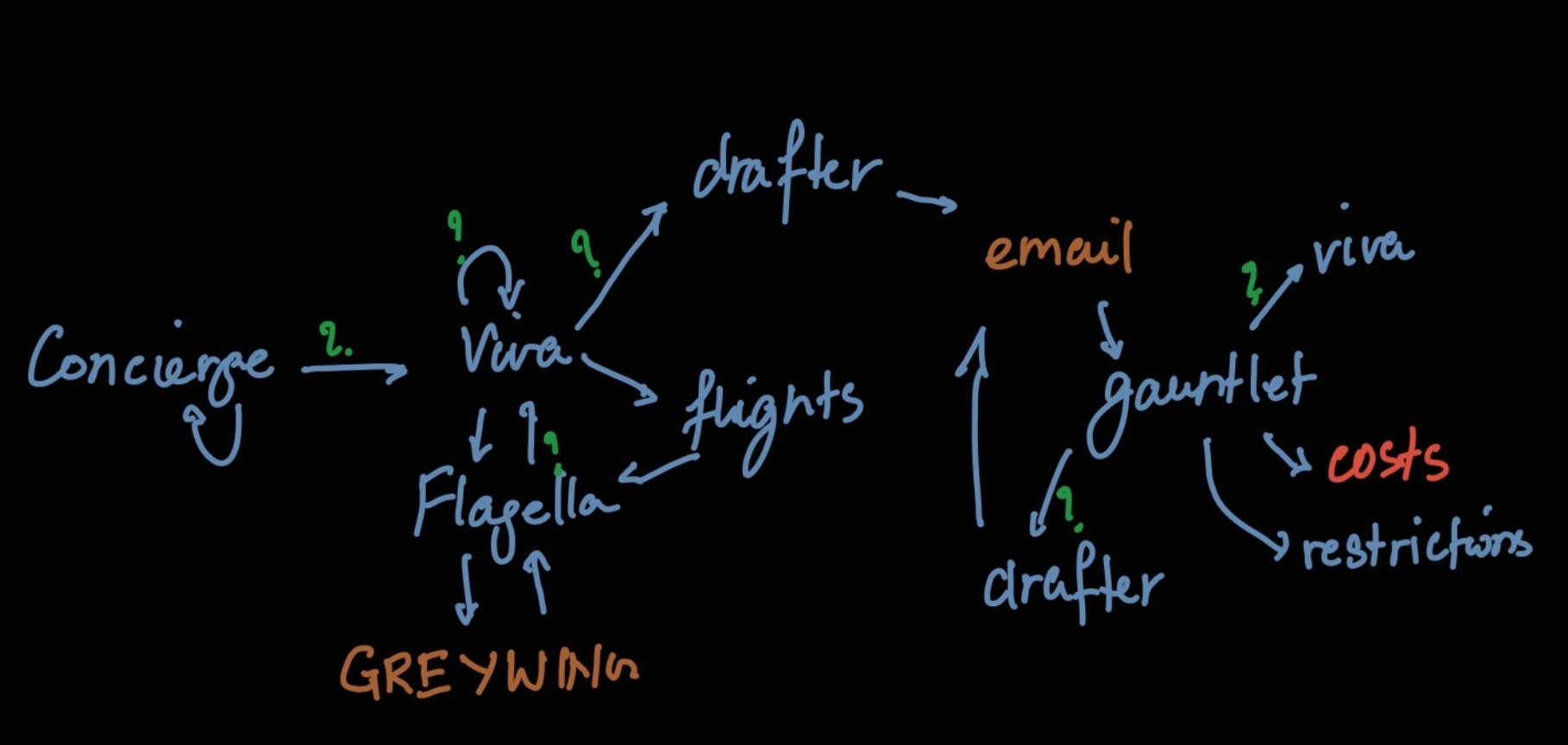
To give you a quick idea, Concierge is the main task distributor agent (an agent in this context being a prompted LLM). Concierge understands what users are looking for and extracts structured data in a format other agents or automated systems can understand. Viva (which I've written about before) is a general purpose data collection module that asks questions to fill in missing data. Flagella is an agent that extracts actions from general purpose prompts and actions them. Gauntlet is a very, very cheap prompt that answers whether more complex prompts need to get involved - and so on.
Everything in orange is an outside system. Green question marks are criticization steps like Reflexion to solidify output and identify errors. Everything in red is a GPT-4 prompt that costs 30 times as much.
This seems like a lot to build, but we've found development accelerating as we go to build the legos we need, to find that we've already got one in our toolkit.
§The why
Breaking agents down this way leads to significantly easier testing, and to locking down reliability that won't be affected by changes to other parts of the system. LLMs are complex brains, which lead to chasing edge-cases, where you change one part of a prompt to fix an edge case, and an entirely unrelated part of the prompt malfunctions. Prompt engineering whack-a-mole.

Upgrades are also significantly easier. We built Viva as a general purpose module to replace the specialised questioning agent we had, and it was a drop-in replacement once we had the interface behaving the same. It took us two minutes to change the function call. Integrating viva with flights took even less time.
But the biggest reason is cost. Only the most complex tasks need to go to GPT-4, and the smaller ones can run on simpler LLMs that run locally (for data security), or GPT-3 for speed and cheaper tokens.
You can also run multiple copies of an agent to perform Self-Consistency with some prompts and not others if you like.
State-management, like rollbacks when an agent fails or investigating root cause with partial state, becomes much easier. Resetting a path to the last working output becomes simple.
Splitting agents this way also helps solve the context problem. Because the most useful context is encapsulated in the structured interface, we can trim past history with abandon without much degradation in experience.
Need I go on?
§How we do it
First, we need some basic tooling. The structured interface is the whole point, and for this we've found the best results leaning against the massive training dataset provided to the LLM. Some cool projects like Guardrails attempt to build their own languages to define structured output.
This works, but remember inference complexity? The more you have to teach it your language, the smaller your budget for actual task completion and inference becomes. We found best results using Typescript specs with added comments - both of which the model is really good at recognizing and generating. Adding a starting character (like { or [ for JSON) reminds the model not to use code blocks or talk in natural language before the object.
The next tool is a coercer for your data. We have something that can take what should be a JSON along with a type spec, and spit out valid JSON. This is something you can also achieve with regexes - the cleaner things are the better everything performs. The key is to use LLMs for what they're good at. If you can leave as much of the deterministic work to code, it gives them more room to be smart.
Larger mistakes that the coercer can't fix are fed back, plus the error, into the original agent with a request to fix. This gets the last 5% of unrecoverable problems out of the way.
§Tips
Build on 'dumber' LLMs. The dumber the LLM (to a point), the more it will expose problems in your prompts instead of papering over them with raw intelligence. Once you have a well-tuned prompt, move up a step and you'll have a lot more options available to you, plus the increased reliability.
Build primitives first - like Data Collection and Merging, Action Extraction, Context Trimming, State I/O.
Once you have those, start with a base intelligence task and then build around it.
§Conclusion
The rise of GPT-4 has led to a large amount of development - as I see it - moving in the direction of big, complex prompts. While I think these are incredibly useful for human-in-the-loop creativity, I strongly believe that building complex, reliable systems will likely need something like the systems we just covered.
Hopefully you found some value herein - I would love to know!

Not a newsletter





