A recommendation engine for blog posts
Imagine my utter surprise when I look for something that can display recommended reading after a blog post, and I turn up nothing. It's always possible I haven't found the right keyword, or I've committed the sin of not using Wordpress or Gatsby. Nothing out there really fits my circumstance and need, even the few that exist for Gatsby and other platforms, so I'll take a weekend shot at building one. Chances are, there's enough copies of my situation out there that this helps someone else.
§What we want
The overall need is simple. I need something that can lead readers into posts they're likely to read after they finish reading one. No pause, no time with family, keep reading. This site - two weeks old now - isn't getting enough reads (about 50K a month) that a perceptron would notice me if I showed up with a boombox. That's fine, I didn't need one anyway. I'd also like to not go broke, so no-cold-start-lambda-functions are a no-go in case I get hugged into poverty by reddit or HN. Let's break it down.
We need a system that will:
- Deliver related posts for each blog post.
- Apply some order to each related post that connects to the likelihood that you'll read it.
- Do as much as possible at build time, and the rest client-side. One is cheap, and the other is free real-estate.
- Be open to analysis so we can realize it's broken and fix it.
- Be adjustable so we can feel like we're fixing it.
- Degrade gracefully in the absence of data.
- Be simple enough to reason about, and with.
That's it. How can we build one?
§What we need
Now that we have a set of constraints, we can impose those on the system that doesn't exist yet.
For 1 (deliver related posts), given a post A, we want a Set of posts (or ids) that are a subset of all posts.
2 (measure likelihood) means we need an order, so let's use an array [B, C, D]. We can use Typescript here to make things simpler.
4 (be investigable) means we need to be able to understand why B is first. We can do this by giving it a value from 0 to 1 as a confidence indicator, and an enum for why it was chosen in the first place. Now we get
type RelatedPost = {
id: string;
confidence: float;
reason: "best-looking" | "cute";
};
type RelatedPosts = RelatedPost[];
3 (split-computation) means we need to actually export our reasoning client-side so we can finish any computations remaining. If we simply had a list of related posts with an order, it would be very hard to add an additional criterion or make modifications.
There are a number of solutions here, but it feels elegant to choose a Symmetric Matrix (a matrix that is symmetric across a diagonal), which should give us some benefits down the line. First, computers understand matrices really well. Most operations are cheap or hardware-accelerated - which doesn't matter to us now, but it might someday when I finish a million posts. Second, we can reason about operations much more easily. With how little I write, I'm going to be a little wasteful and store the entire matrix, but we can always fold and unfold it later if we need to.
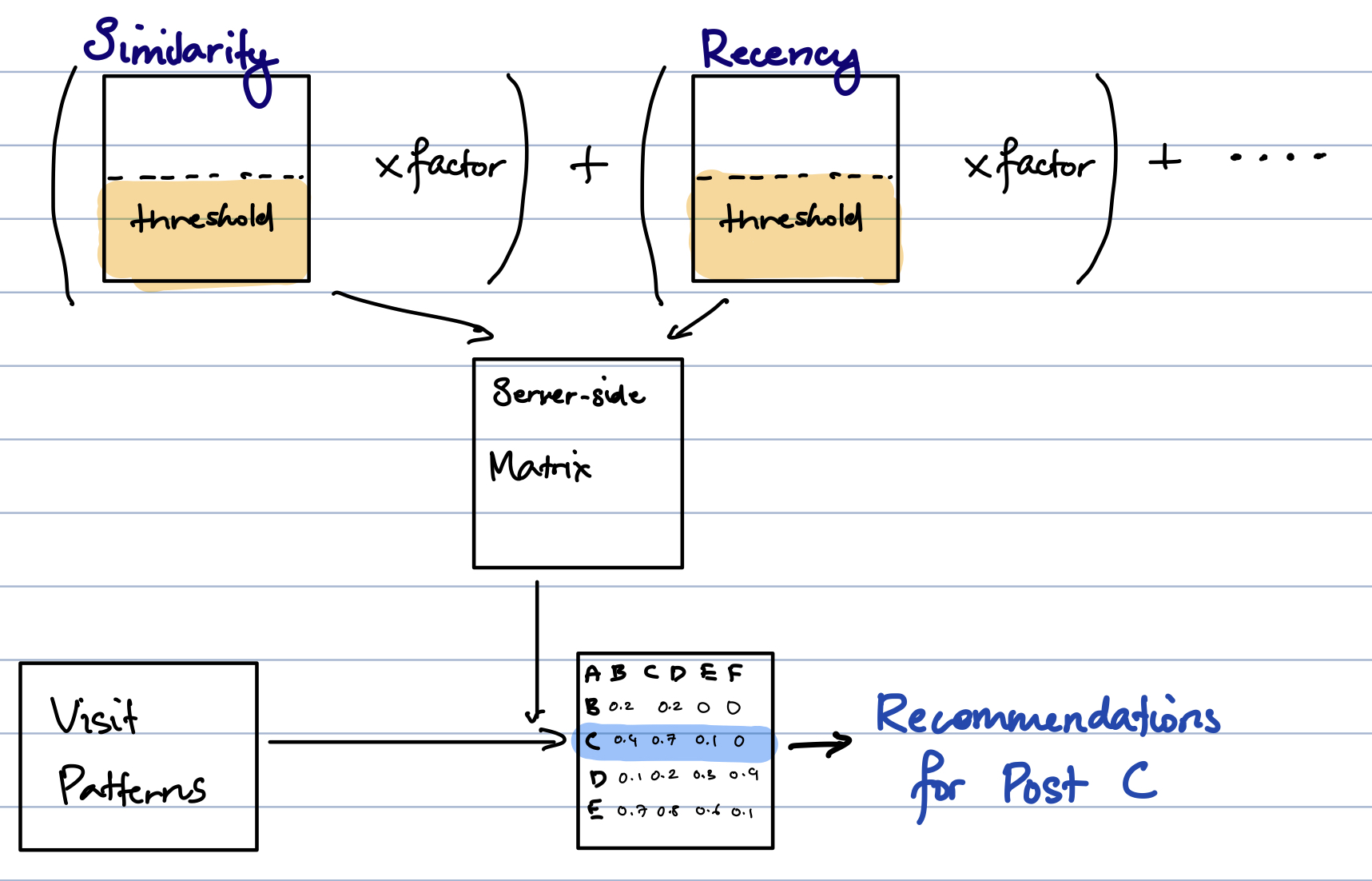
This way, we can store our likelihood expectations from all posts to all posts, like so:
type DistanceMatrix = {
identifiers: string[];
matrix: number[][];
}
Now, we need 5, which means adjustability. We also need 6, which means we need to know what we have data for and what we don't. My solution to this has been to generate matrices for each reason/property that a post would become related to another, and combine these likelihood matrices with some multiplier. That way, we can add a minimum likelihood threshold so weaker reasons will take themselves out of the equation. We can also over and under-weight reasons in a way that makes sense to us, and make things adjustable.
type RelatedPostMetric = {
id: string;
description: string;
threshold: number;
multiplier: number;
}
type Metrics = RelatedPostMetric[];
We also added a vector in there so we can take into account reasons that a post should be displayed that has nothing to do with any other post. We'll see an example as we go on.
Next, let's consider these reasons.
§What we have
We can list the properties of a post that would be relevant for computing the likelihood that it's related to another post.
(YMMV, but the system we build should be adjustable so you can add your own.)
- Category/Metadata: If you use tags and categories, similarity here implies your personal opinion that two things belong in the same box. It's the only real opinion you've got, so we're putting it at the top.
- Title similarity: If two posts have the same proper nouns, chances are they're related.
- Text similarity: Prone to errors unless fed a mountain of training data, this is still a good fallback.
- Recency: This is our current final fallback. If we can't find anything related, we hope you'll be interested in the latest of things.
§Putting it together
Now that we have these, the overall logic is simple. We go through the categories in order or priority, generate the matrix or vector, cut off all values below a certain threshold, and boost it with some multiplier. Once that's done, we add it to the a global matrix.
Depending on how the pipeline is separated, we can generate this matrix at build-time, add more properties at serve time, and then again client-side. The matrices themselves are human-readable json and easy to reason about. I've linked the matrices that currently power this blog here.
Finally, we'll add a simple function to keep track of the strongest category for each likelihood (so we know why a post is being recommended).
And we're done! In < 300 lines of typescript, we have our recommendation engine.
§But what about X?
There are a number of reasons for recommending a post that I haven't included here for simplicity - and I'm always open to ideas. The core of this work has been to build something that can stand up to repeated extension and tuning, with minimal data to work from and is simple enough to be used elsewhere.
I've hosted the file in this gist if you'd like to try it out. The salient parts are below:
export type RelatedPosts = {
slugs: string[],
categories?: string[],
frontmatters: (FrontMatter | null)[],
};
export type RelatedPostMatrices = {
[index: string]: RelatedPosts
}
type DistanceMatrix = {
identifiers: string[],
matrix: number[][],
strongestCategories?: number[][],
}
type StrengthVector = {
identifiers: string[],
vector: number[]
}
type RelatedPostMetric = {
id: string;
description: string;
threshold: number;
multiplier: number;
}
const metrics: RelatedPostMetric[] = [
{
id: 'titles',
description: 'Similar',
multiplier: 8,
threshold: 1
},
{
id: 'tagCats',
description: 'Same Category',
multiplier: 10,
threshold: 1,
},
{
id: 'content',
description: 'Similar',
multiplier: 8,
threshold: 0.91
},
{
id: 'recency',
description: 'New',
multiplier: 1,
threshold: 0.3
}
]
function applyMatrixThreshold(distanceMatrixVector: DistanceMatrix | StrengthVector, threshold: number): DistanceMatrix | StrengthVector {
if('matrix' in distanceMatrixVector)
return {
identifiers: distanceMatrixVector.identifiers,
matrix: distanceMatrixVector.matrix.map(col => col.map(row => !isNaN(row) && row <= threshold ? row : 1))
}
else
return {
identifiers: distanceMatrixVector.identifiers,
vector: distanceMatrixVector.vector.map(v => !isNaN(v) && v <= threshold ? v : 1 )
}
}
function normalizeVector(vector: number[]) {
const normalizeVal = (val: number, max: number, min: number): number => {
return(val - min) / (max - min);
}
const max = Math.max.apply(null, vector);
const min = Math.min.apply(null, vector);
const normalizedVector = vector.map(val => normalizeVal(val, max, min));
return normalizedVector;
}
function applyFunc(incoming: DistanceMatrix | StrengthVector, func: (inp: number) => number) {
if('matrix' in incoming) {
return {
...incoming,
matrix: incoming.matrix.map(r => r.map(c => func(c)))
}
} else {
return {
...incoming,
vector: incoming.vector.map(r => func(r))
}
}
}
function customSigmoid(inp: number): number {
return 1./(1.+Math.exp(-8.*(inp-0.5)))
}
function invertNormalized(inp: number): number {
return 1-inp;
}
function convoluteAddWithMultiplier(baseMatrix: DistanceMatrix, incoming: DistanceMatrix | StrengthVector, multiplier: number): DistanceMatrix {
if('vector' in incoming) {
incoming.vector = incoming.vector.map(val => val*multiplier);
baseMatrix.matrix = baseMatrix.matrix.map((r, rowIndex) => r.map((c, colIndex) => incoming.vector[colIndex]+c));
} else {
incoming.matrix = incoming.matrix.map(row => row.map(val => val*multiplier));
baseMatrix.matrix = baseMatrix.matrix.map((r, rowIndex) => r.map((c, colIndex) => incoming.matrix[rowIndex][colIndex]+c));
}
return baseMatrix;
}
export function checkBuildRelatedPosts() {
if(!fs.existsSync(relatedPostsFile))
generateRelatedPosts();
}
export const generateRelatedPosts = () => {
console.log("Building related posts");
const posts = getAllPosts(true);
console.time("Generating corpus");
const postTitleCorpus = new Corpus(posts.map(post => post.slug), posts.map(post => post.frontmatter.title + post.frontmatter.description));
const postTagCategoryCorpus = new Corpus(posts.map(post => post.slug),
posts.map(post =>
(((post.frontmatter.categories && post.frontmatter.categories.join(" ")) || "")+
((post.frontmatter.tags && post.frontmatter.tags.join(" ")) || "")) || (post.frontmatter.title + post.frontmatter.description)
)
);
const postContentCorpus = new Corpus(posts.map(post => post.slug), posts.map(post => post.markdown));
console.timeEnd("Generating corpus");
console.time("Computing metric data");
const metricData: {
[index: string]: DistanceMatrix | StrengthVector
} = {};
for(let i=0;i<metrics.length;i++) {
switch(metrics[i].id) {
case 'titles':
metricData[metrics[i].id] = new Similarity(postTitleCorpus).getDistanceMatrix() as DistanceMatrix;
break;
case 'content':
metricData[metrics[i].id] = new Similarity(postContentCorpus).getDistanceMatrix() as DistanceMatrix;
break;
case 'tagCats':
metricData[metrics[i].id] = new Similarity(postTagCategoryCorpus).getDistanceMatrix() as DistanceMatrix;
break;
case 'recency':
metricData[metrics[i].id] = applyFunc(
{
identifiers: posts.map(post => post.slug),
vector:
normalizeVector(
posts.map(post => post.frontmatter.date ? (new Date().getTime()-new Date(post.frontmatter.date).getTime()) : 0),
)
}, customSigmoid);
break;
default:
throw new Error("Metric detected without any data generation code.");
}
// Fix this when you land
metricData[metrics[i].id] = applyMatrixThreshold(metricData[metrics[i].id], metrics[i].threshold);
metricData[metrics[i].id] = applyFunc(metricData[metrics[i].id], invertNormalized);
}
console.timeEnd("Computing metric data");
console.time("Convoluting...");
let finalMatrix: DistanceMatrix = {
identifiers: JSON.parse(JSON.stringify(metricData.titles.identifiers)),
matrix: (metricData.titles as DistanceMatrix).matrix.map(r => r.map(c => 0)),
}
let strongestCategories = (metricData.titles as DistanceMatrix).matrix.map(r => r.map(c => null as null | {category: number, val: number}));
for(let i=0;i<metrics.length;i++) {
const metric = metrics[i];
let incoming = metricData[metric.id];
finalMatrix = convoluteAddWithMultiplier(finalMatrix, incoming, metric.multiplier);
if('matrix' in incoming) {
incoming.matrix.map((r, rIndex) => r.map((c, cIndex) => {
const newVal = c * metric.multiplier;
const existingVal = strongestCategories[rIndex][cIndex];
if(!existingVal || existingVal.val < newVal)
strongestCategories[rIndex][cIndex] = {
category: i,
val: newVal
}
}));
} else {
incoming.vector.map((r, rIndex) => {
const newVal = r * metric.multiplier;
strongestCategories.map((sc, scIndex) => {
const existingVal = strongestCategories[rIndex][scIndex];
if(!existingVal || existingVal.val < newVal)
strongestCategories[rIndex][scIndex] = {
category: i,
val: newVal
}
});
});
}
}
finalMatrix.strongestCategories = strongestCategories.map(r => r.map(c => c && c.category || 0));
console.timeEnd("Convoluting...");
console.time("Writing to file...");
fs.writeFileSync(relatedPostsFile, JSON.stringify({...metricData, final: finalMatrix}));
console.timeEnd("Writing to file...");
}
export function getRelatedPosts(slug: string): RelatedPostMatrices {
checkBuildRelatedPosts();
const matrices: {
[index: string]: DistanceMatrix | StrengthVector
} = JSON.parse(fs.readFileSync(relatedPostsFile));
let slugIndex = matrices.final.identifiers.findIndex(val => val === slug);
if(slugIndex === -1)
slugIndex = 0;
let relatedPosts: RelatedPostMatrices = {};
Object.keys(matrices).map(type => {
if('matrix' in matrices[type]) {
const scores = (matrices[type] as DistanceMatrix).matrix[slugIndex]
.map((score, index) => ({score, index}))
.sort((a,b) => {
return b.score-a.score
})
.filter(score => score.score > 0 && score.index !== slugIndex);
relatedPosts[type] = {
slugs: scores.map(score => matrices[type].identifiers[score.index]),
frontmatters: scores.map(score => {
try {
return getCondensedPost(getFileNameFromSlug(matrices[type].identifiers[score.index])).frontmatter
} catch(err) {
console.error("Error reading frontmatter for slug ",getFileNameFromSlug(matrices[type].identifiers[score.index])," - ",err);
return null;
}
})
}
if((matrices[type] as DistanceMatrix).strongestCategories) {
relatedPosts[type].categories = scores
.map(score => (matrices[type] as DistanceMatrix).strongestCategories![slugIndex][score.index])
.map(catIndex => metrics[catIndex].description)
}
} else {
const scores = (matrices[type] as StrengthVector).vector
.map((score, index) => ({score, index}))
.sort((a,b) => b.score-a.score);
relatedPosts[type] = {
slugs: scores.map(c => matrices[type].identifiers[c.index]),
frontmatters: scores.map(score => {
try {
return getCondensedPost(getFileNameFromSlug(matrices[type].identifiers[score.index])).frontmatter
} catch(err) {
console.error("Error reading frontmatter for slug ",getFileNameFromSlug(matrices[type].identifiers[score.index])," - ",err);
return null;
}
})
}
}
})
return relatedPosts;
}

Not a newsletter