Real results from a month of running an AI network
I'm interested in how far Rakis gets before it fails - and why it'll fail.
This is what we had at the top of the launch Rakis post. It has been about a month, two thousand nodes, 10 million tokens processed and over a thousand AI workers run, what did we learn?
What worked and what didn't? (The complete set of interactive graphs is linked at the end, along with the dataset).
Here's a quick refresher on the key concepts.
§Running AI networks on the web
To start, Rakis is the first completely in-browser peer-to-peer inference network I know. There were no servers - the client-side code was distributed on Vercel and Huggingface, or by running it yourself with bun start from Github. This has been a tradeoff.
The good side of that tradeoff is that the barrier to entry on a browser is as low as it gets - and it shows. Just over a quarter of all visitors sent an inference request:
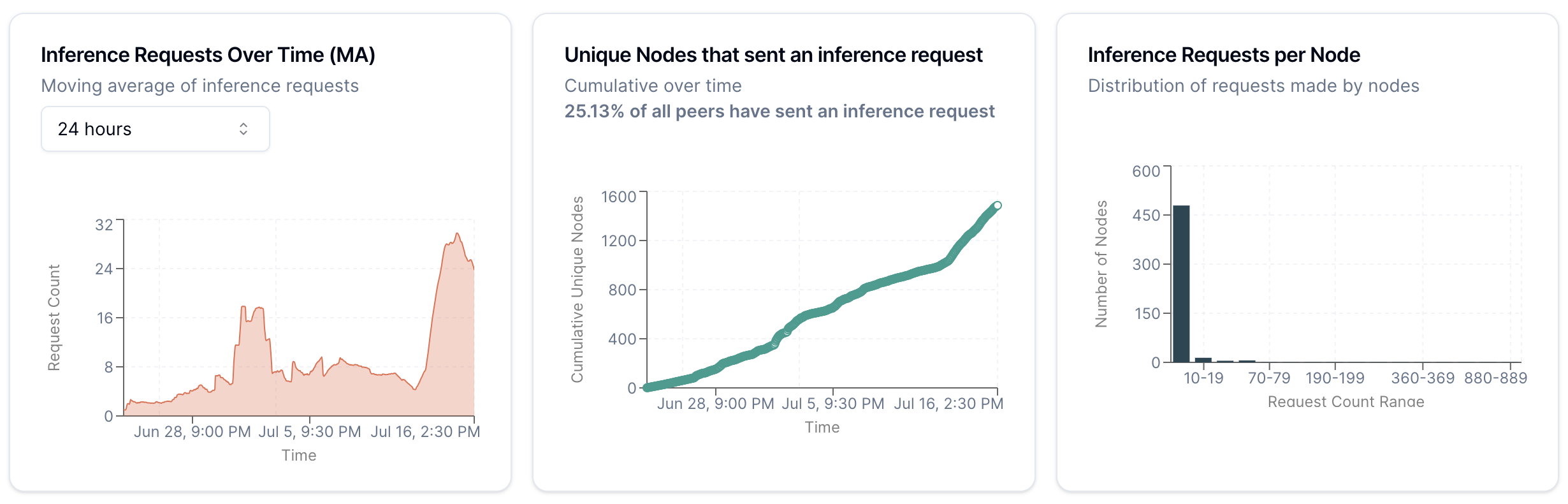
Over 15% of all visitors ran AI models completely in their browser and participated in the network:
This simply blows my mind - when we consider that this is a percentage of what is effectively pageviews on the web.
The bad side of the tradeoff is that the data we use can't be said to exhaustively cover the entire network. Network partitions, system load, and a number of things affect a single node's ability to see the state of the entire system. We've also had to trim our packets in a forward-looking attempt to minimize the hit on the filesystem, so nodes only keep the last 5000 packets. (Turns out this was unnecessary, but you can't go back and create information that's erased).
This is pretty clear from looking at the difference between token counts reported by other nodes, and the specific tokens processed by our node.
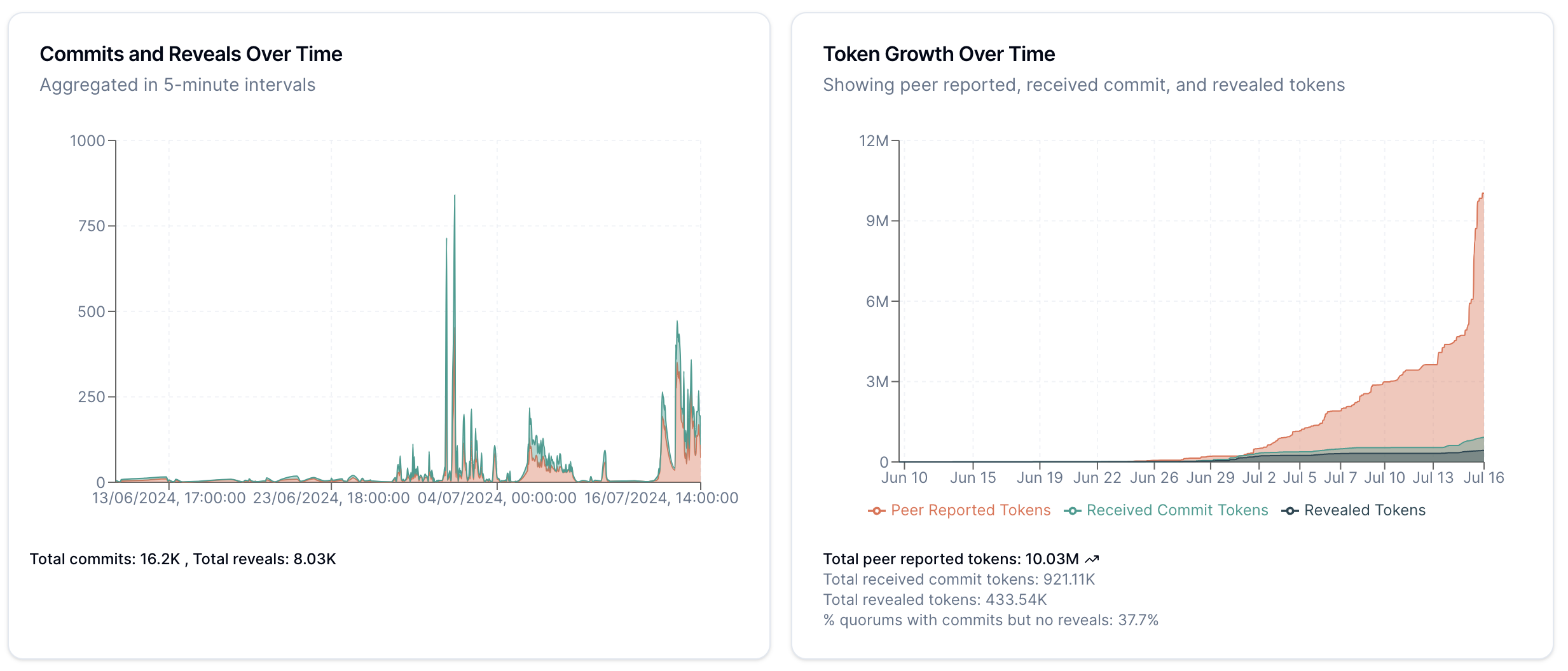
Looking at moving averages we can see a big difference.
Something to note is that reported token counts from peers are not the same as the token counts we see in the network. This is because we don't store the peer's reported token count except the last time we saw them. This means that we can't use the reported token count as a proxy for the actual token count, and we have to use the token count we see in the network. In storing node information for this analysis we had to make the tradeoff between choking the network with transmissions and having less information.
If we use a second node sitting elsewhere to investigate differences over time, we can see instabilities.
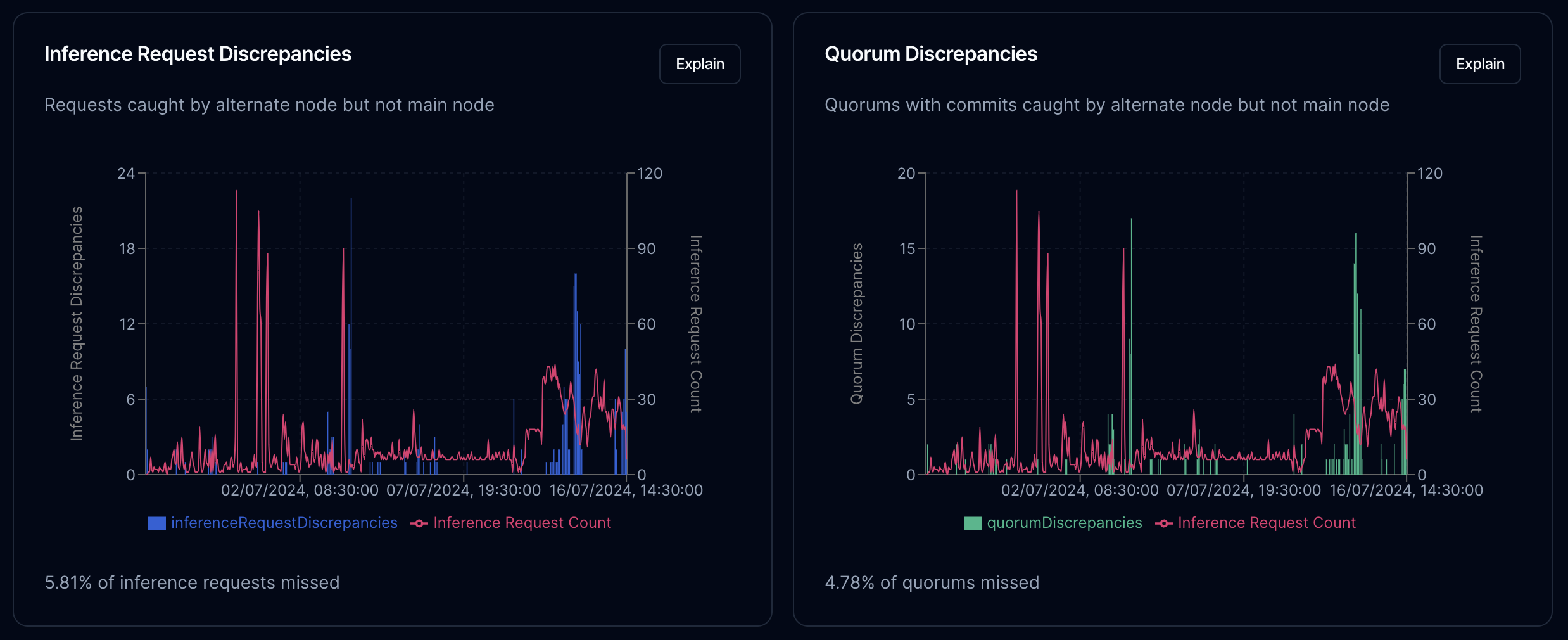
We see about a 5% difference between what one node saw that the other didn't, in both inference requests and results seen. This is pretty good for two machines that sat on different continents, on different operating systems, with very different internet connections.
This difference however, also causes an issue with consensus. To repeat the basics of Rakis, requests for inference come into the network, where nodes compute the results, commit to them, and after a period reveal them for consideration.
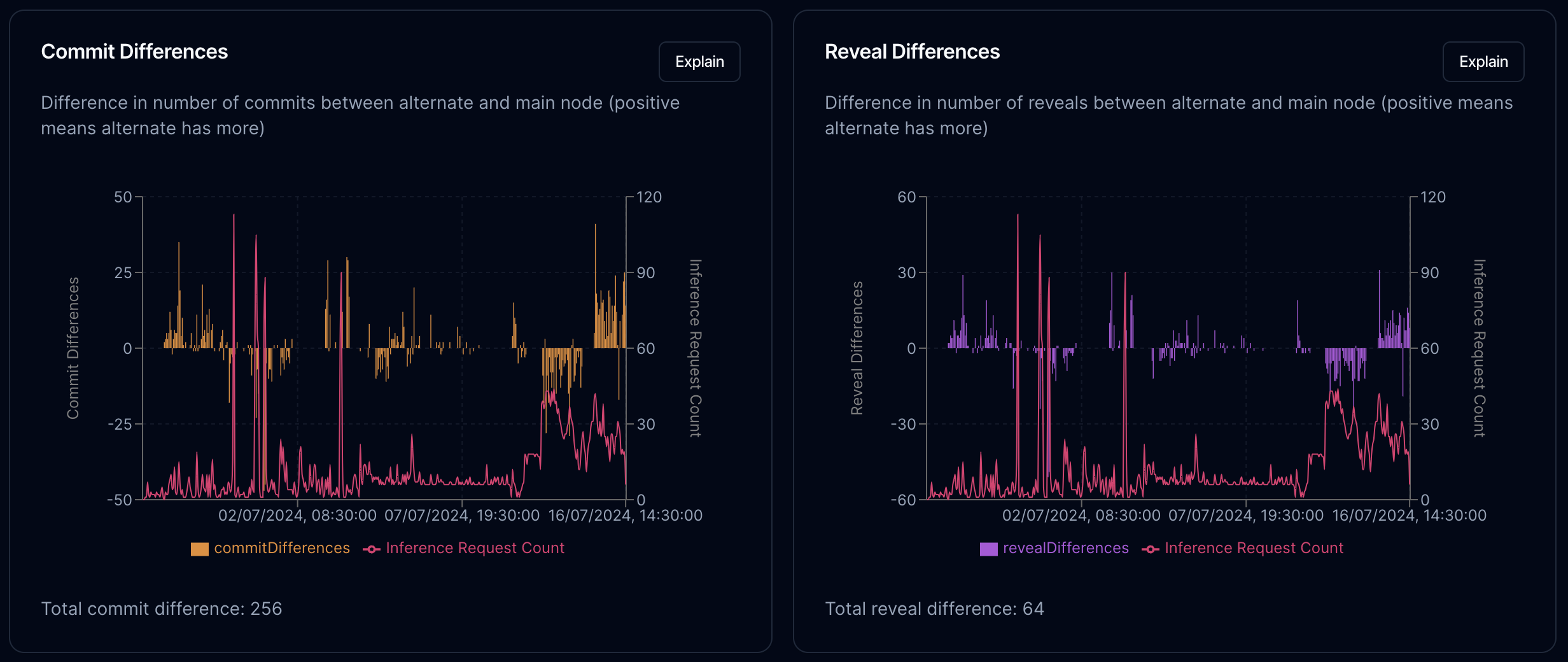
Looking at our two nodes, we can see positive and negative fluctuations in the number of commits and reveals that each node can see (for the same request). This correlates somewhat with sustained load as we can see on the graph. The two big inference batches that came into the network don't seem to have caused a big change, but the period of sustained inference requests we're seeing now seems to be causing something of a divergence.
We'll discuss potential solutions for this later on. First, let's look at the external systems that Rakis was built on.
§Chains and P2P Networks
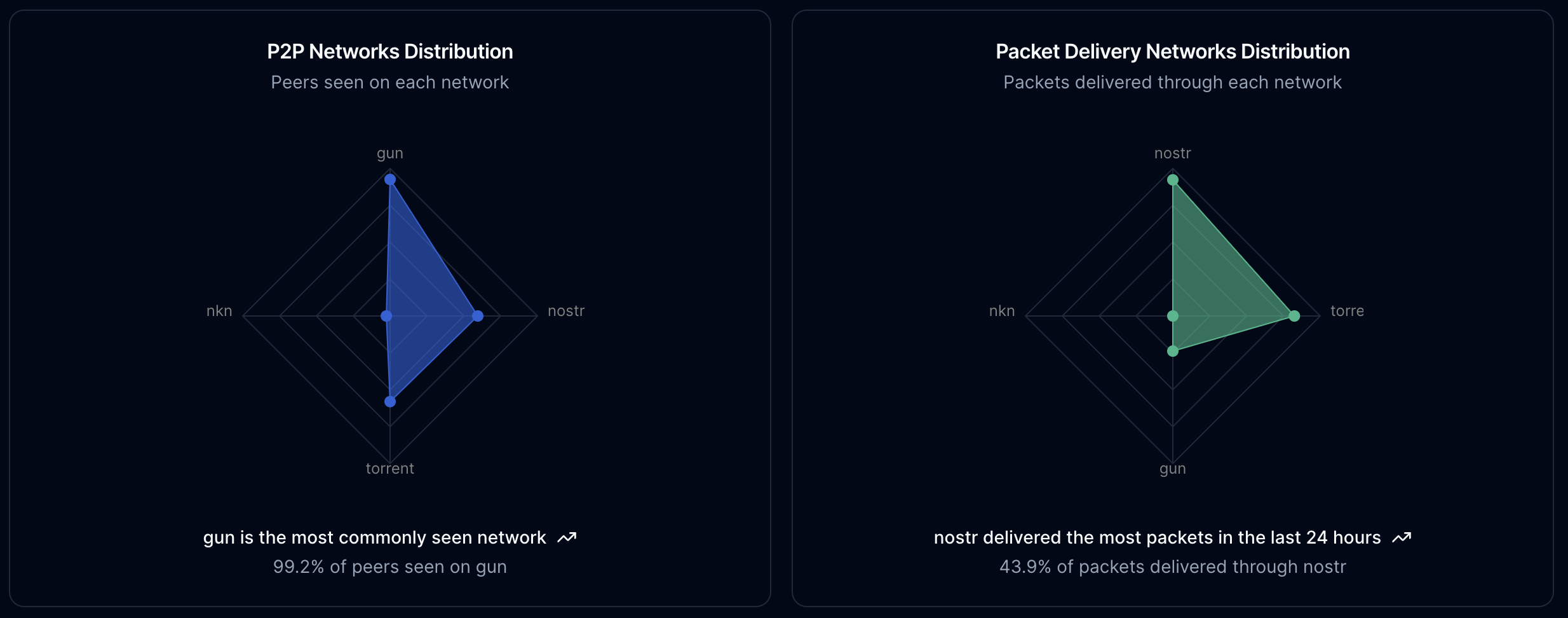
The way that packet delivery works in Rakis is by using PewpewDB, NKN, the nostr and torrent networks through Dan Motz's awesome Trystero as redundant channels. Nodes ignore retransmitted packets and hold on to the first received packet. We also maintain a list of which networks we've ever seen a peer on.
With this knowledge, we can see that gun has delivered packets from almost every peer. Looking at the most recent packets however, it seems the torrent network is the fastest. Given that trackers are often disabled in some networks, it could be that in my part of the network, torrents were still allowed.
The packets we're using here are from a different time period (more recent than the snapshot) of the same node. Packets are auto-scrubbed to keep the node storage small, and we turned it down for a short period and use this data to extrapolate out.
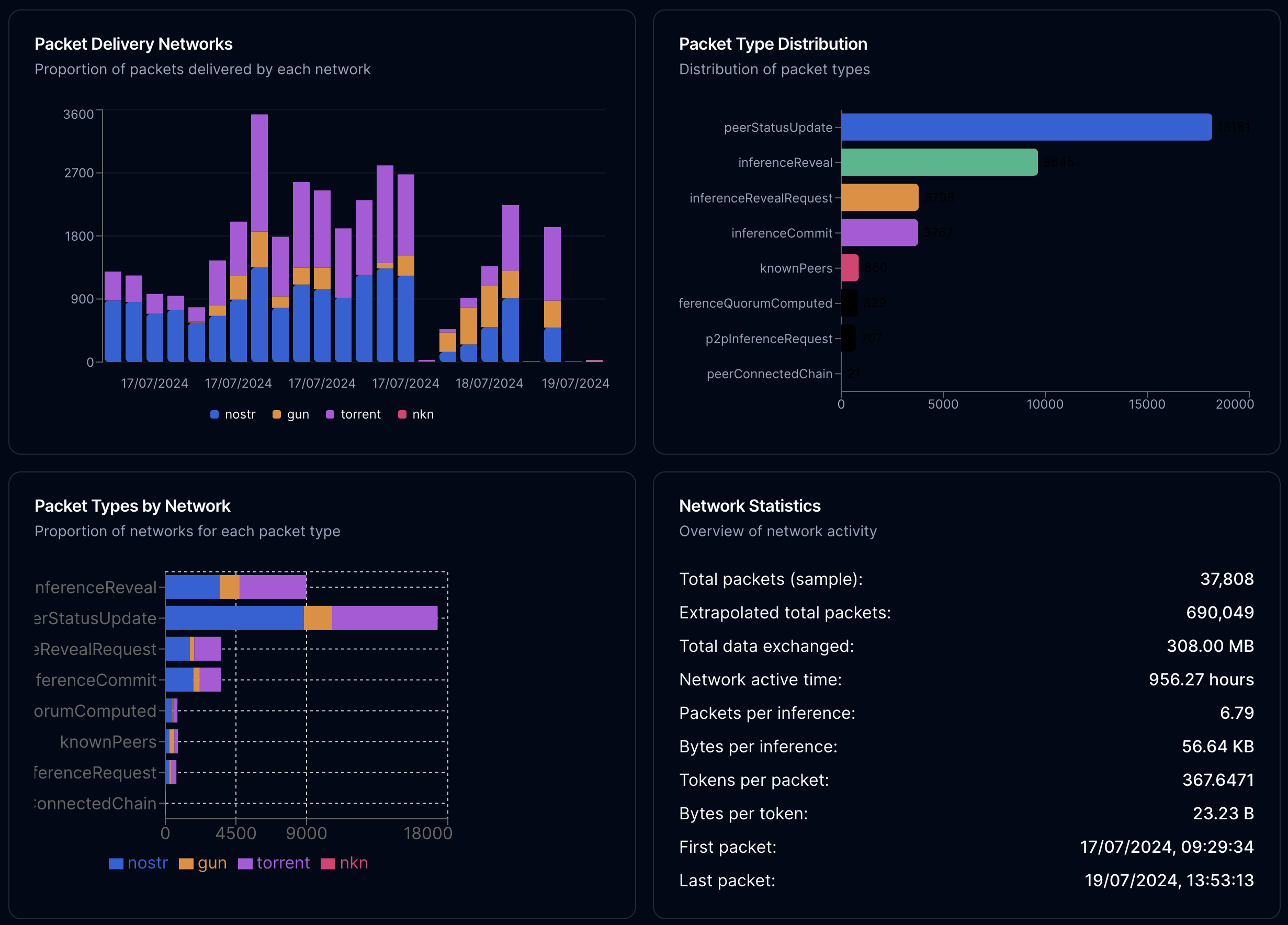
If we ignore redundant transmissions and use the packet sizes as a proxy, we get about 23 bytes per token inferenced on the network. This isn't useful to us until more AI inference networks exist, and reveal their transmission cost, but it can also serve as a benchmark for us in the future.
We also see that we get about 300 tokens per packet sent, which is a pretty good level of efficiency for a decentralized network - but I suspect we can do another 10-50x better given time and engineering.
What's also interesting is that the type of packet being sent doesn't affect the general ratio of delivery networks that get it through. My original expectation was that some networks would perform better for large packets (like inference reveals, which have outputs and embeddings), but this doesn't seem to be the case.
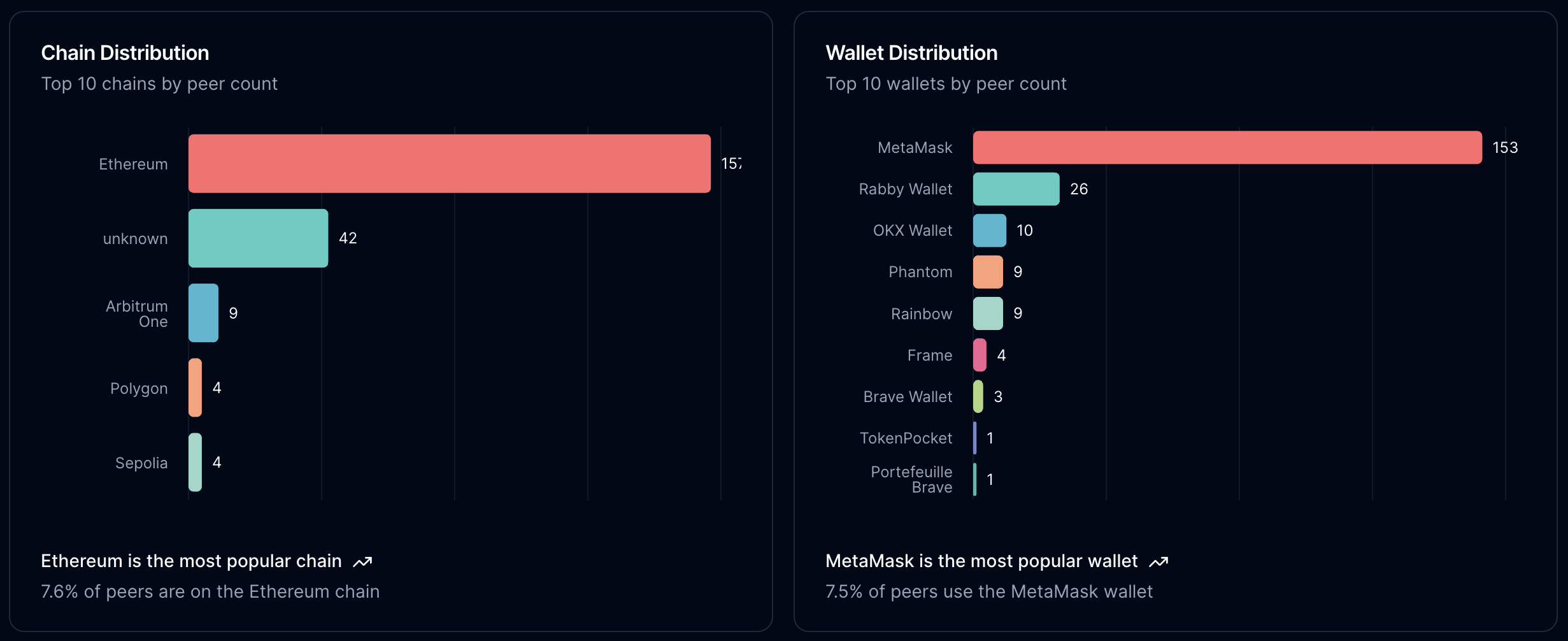
Eth was the most popular chain among users that connected wallets. For the stability test, only EVM chains were counted. Wallet distribution was surprising - both me and Julian expected Phantom to be much higher on this list.
§Node participation
Despite the limited publicity we gave Rakis (not much was done other than some DMs and a few twitter posts), the participating node count was quite healthy during the stability test.
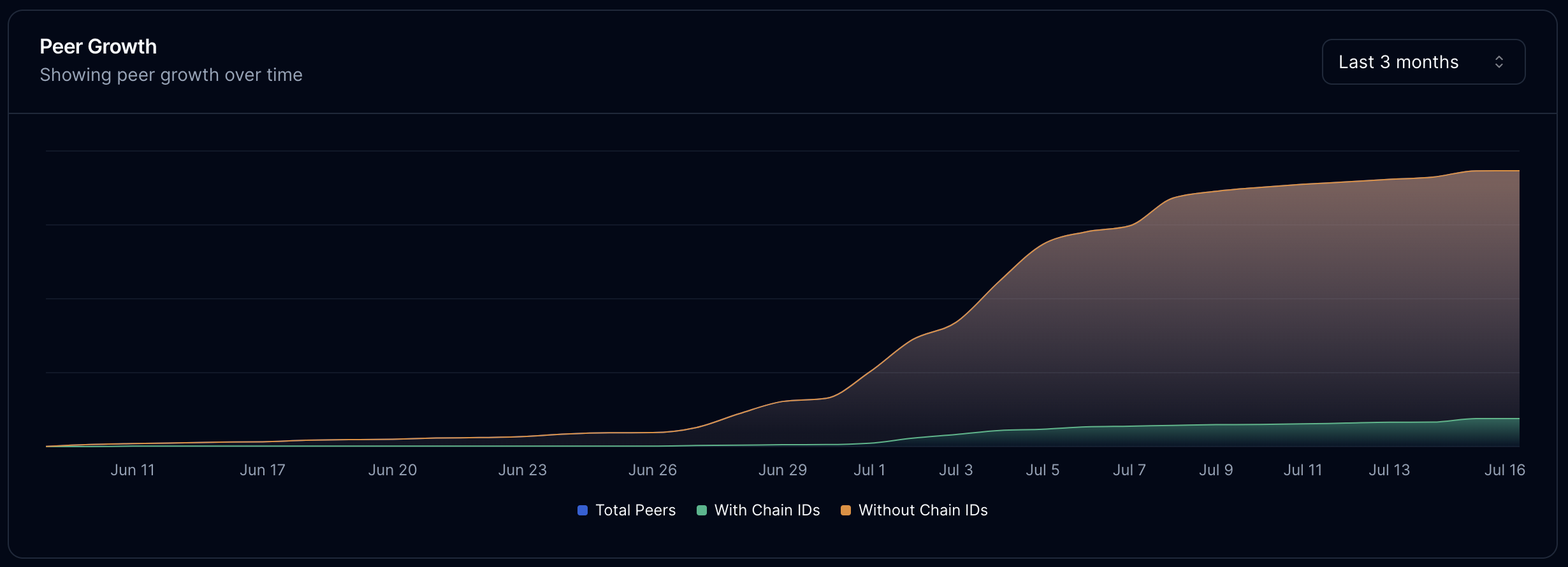
As of late, we've seen a drop in node count but an increase in number of available AI workers. Our thinking is that non-inferencing nodes drop off once curiosity runs its course.
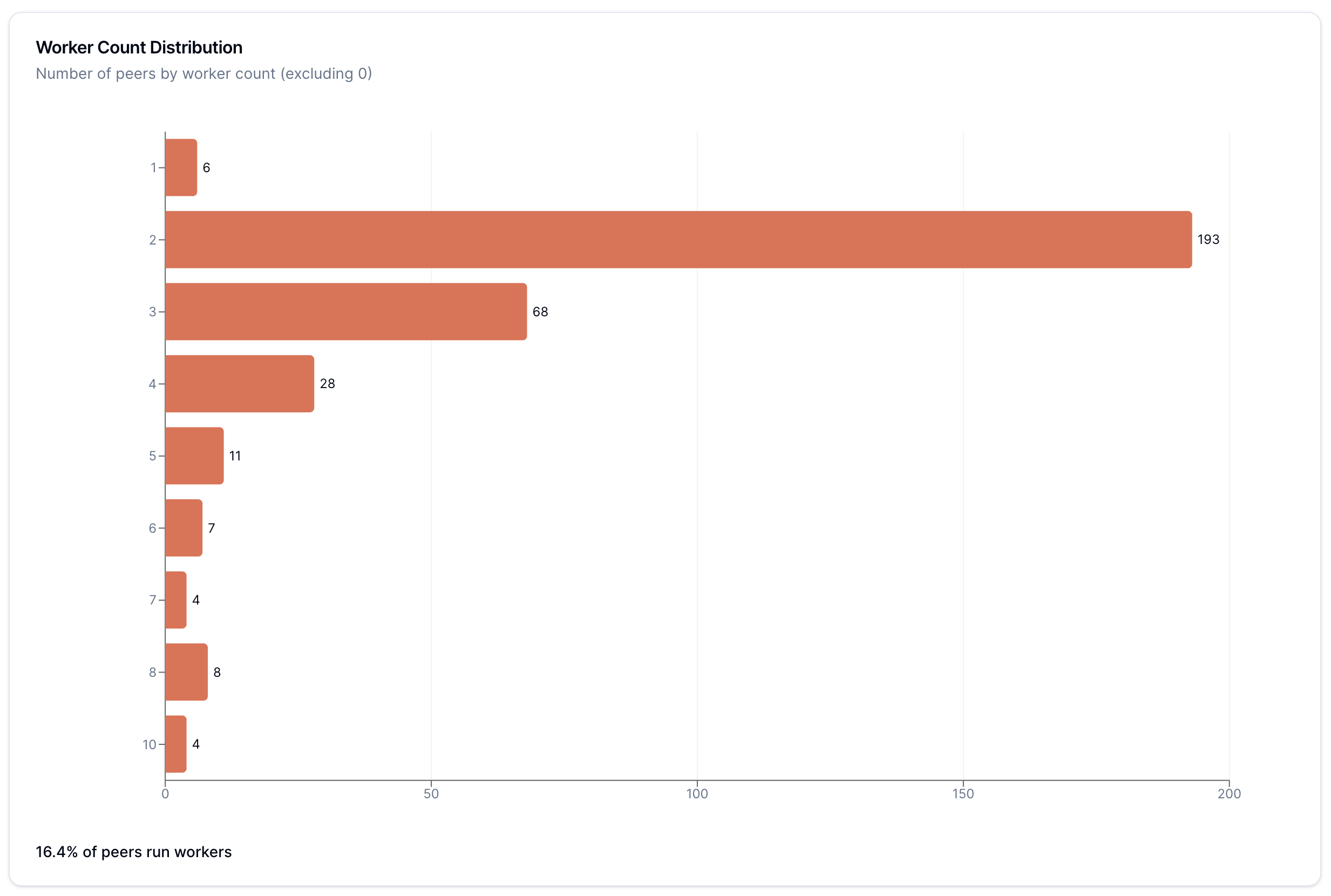
Excluding nodes that didn't run workers, most nodes ran the default 2 workers (as seen from the Worker Count Distribution chart). However, what's interesting is that the dropoff on either side remains relatively smooth. I have no immediate explanation for this.
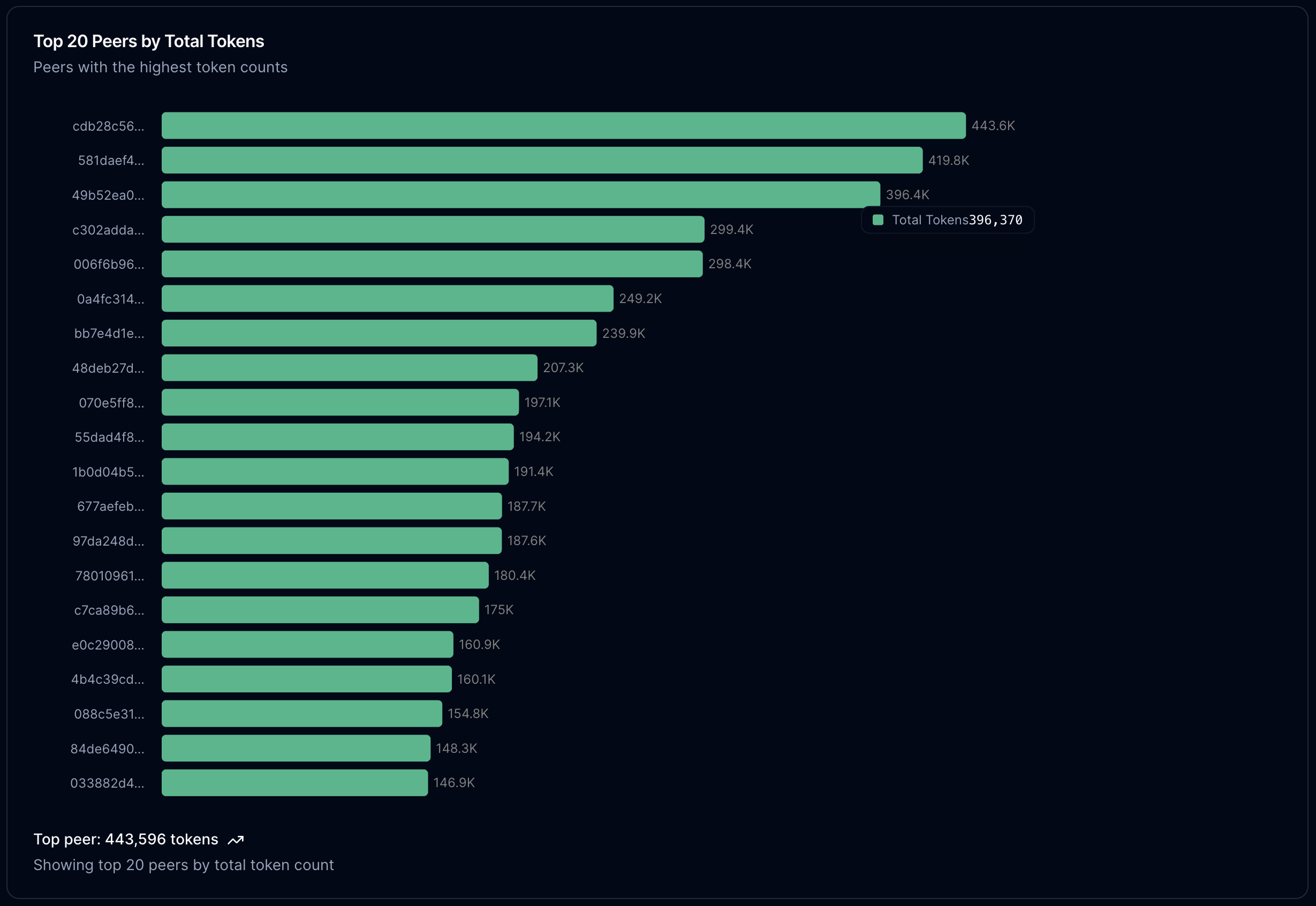
If we look at the number of inference tokens that peers have contributed to the network, two things are fascinating:
- Our nodes aren't the highest performing nodes, by the number of tokens. Despite being the longest-lived nodes on the network, a few other nodes have outpaced our own nodes.
- The dropoff in the number of tokens inferenced by nodes is relatively smooth and unimodal, indicating that the compute power per node is relatively equal, compared to server-based inference.
Now we come to the most important part.
§Consenus
The key problem in a trustless AI network is consensus. The only way to be sure of honesty is for nodes to check each other, and verify outputs. Given that AI models are non-deterministic at useful sizes, we need a consensus algorithm that can be repeated and still yield the same output.
The way that Rakis does this is by using embeddings. Nodes commit and reveal repeated inferences for the same output, which are clustered in embedding space, with a consensus grouping that is adjustable by the requester. You can read more in this part of the launch post, but here's a plot of embeddings from a few requests highlighted:

We can see outputs from the same requests clustered together. Before the launch, we set what we believed were reasonable hyperparameters for the consensus process - but nothing survives contact with a large network of peers we've never met. So how did things turn out?
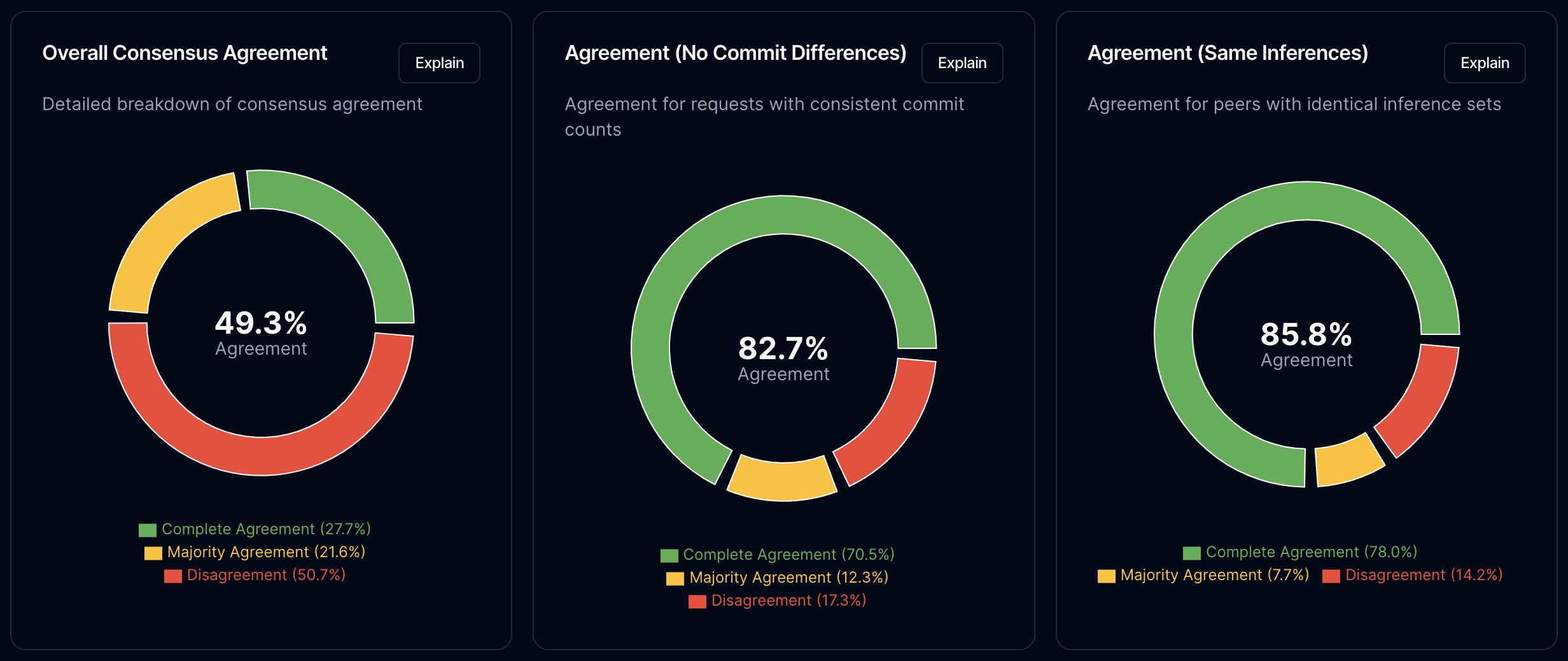
27.7% of all quorums computed by this node agreed 100% with the rest of the network. For how much partitioning we are now seeing on the network, this is a pretty good number. If we look at Majority Consensus (>50% of nodes must agree), we see about 49.3.4%.
The biggest factor for failed consensus calculation is that nodes didn't always see the same commits and reveals. Partly this is caused by the default period of 20 seconds being too low for this information to propagate. Another possible culprit is that nodes prioritized generating inferences (which lead to commits) over revealing their inferences - a sad but easily fixable problem.
If we correct for commit differences by count, the consensus percentage jumps to 82.75%. If we then check to make sure the sets of commits received are the exact same, we get 85.8%.
That final ~15% is likely coming from non-determinism in the embedding calculation. As each node verifies commits, it rechecks the embedding and hash calculations and discards any commits that failed verification. If we look at the occurrence, we see that this is not an insignificant percentage.
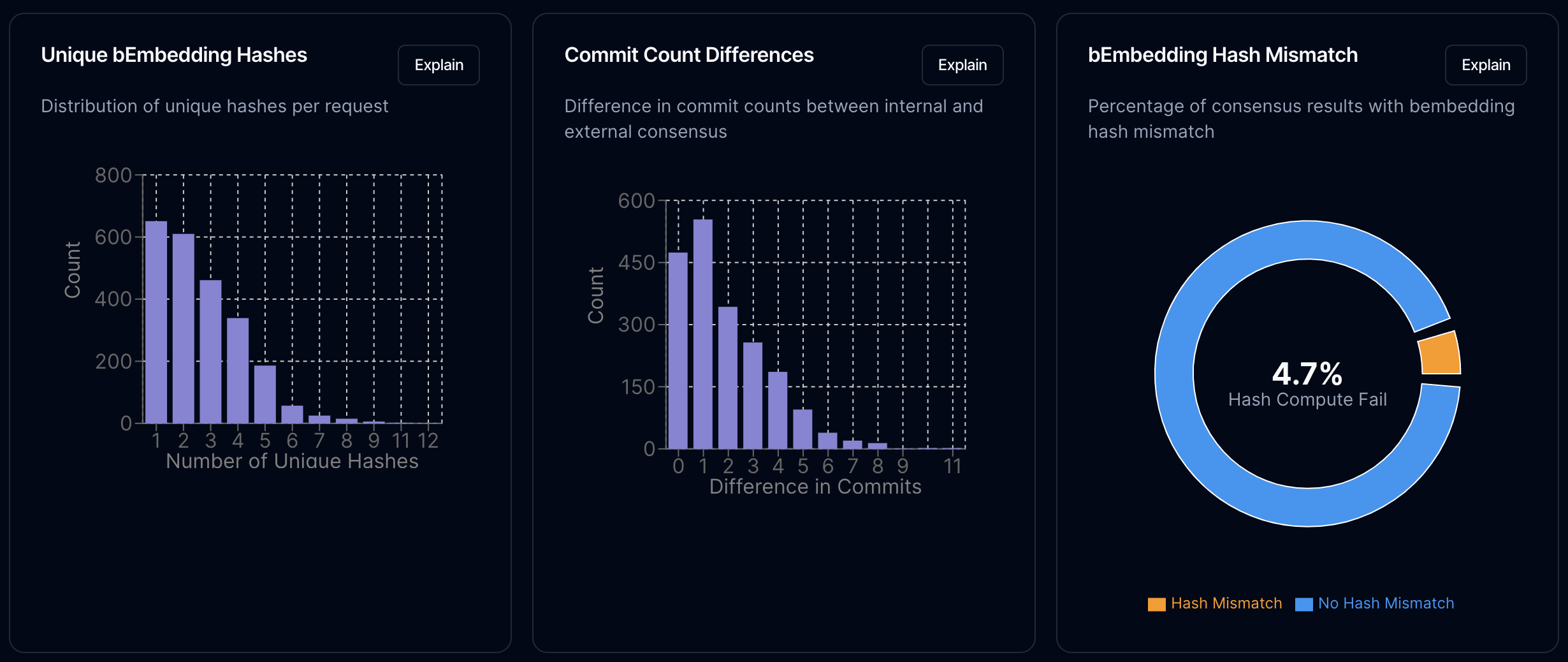
This is something we expected. The Rakis codebase already has a method to check for a threshold when validating embeddings (instead of a one-to-one comparison), but this was left off for the stability test to highlight non-determinism.
We also see a high difference in number of commits being processed for the same inference request by different nodes. The key - as the theme of this test is turning out to be - is learning to deal with delayed transmission and network partition.
What is really interesting is how the cluster distance held up to the variety of inference requests received by the network, and the number of participating nodes. If we look at the average distance between embeddings in each cluster, we see a nice normal curve. This is very, very promising for embeddings (albeit with some added complexity) as a consensus mechanism. What I'm reading from this graph is that a distance of 720 would cover 94% of all inferences.
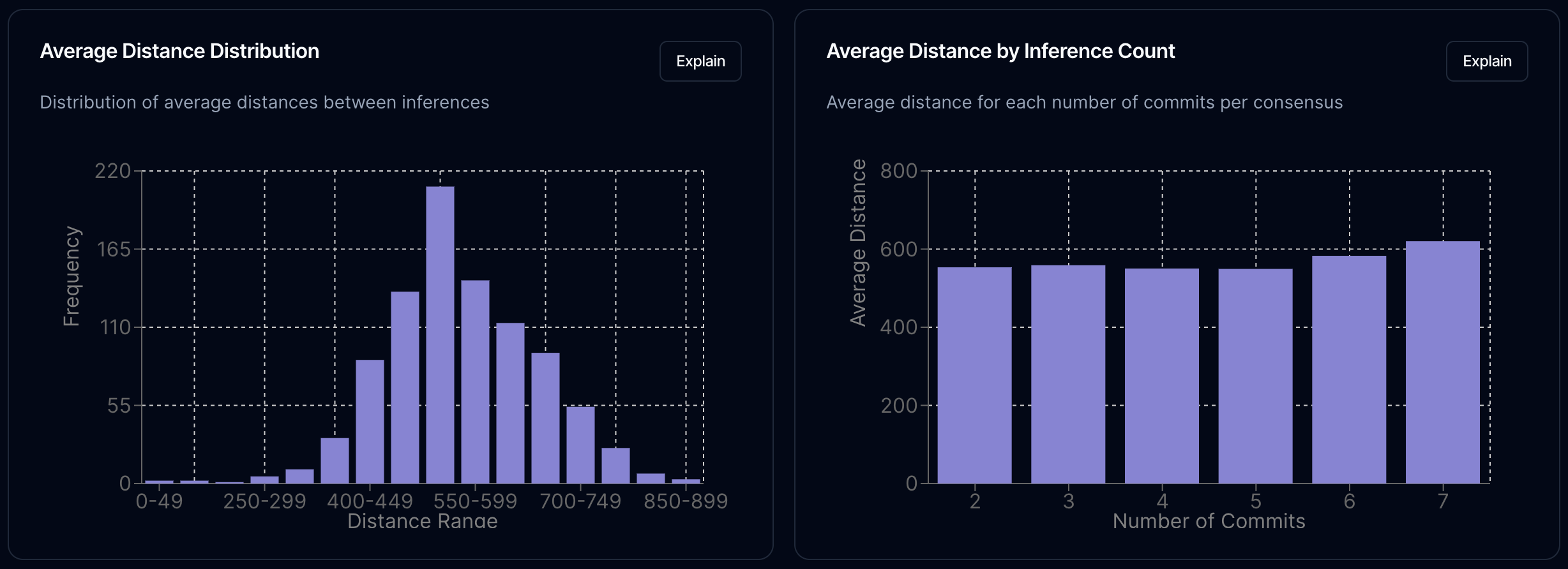
We also see that the average distance doesn't increase much when we add more commits. This is also promising. If we remember, the temperature for output generation was set to one when generating outputs. From the first stability test, the system seems robust even with this much entropy.
The full set of outputs from the stability test are on this map from Nomic:

§Long-term stability
The last thing we wanted to see was whether the network would hold up over a longer period. Given that Rakis was built in ten days, we worried there might be bugs that crashed workers and nodes across the network as storage, computing and communication needs expanded.
This didn't happen. Looking at our node, we maintained a pretty stable TPS throughout our run, with spikes in network TPS and request rates not affecting the node's ability to run inference and contribute computing power.
§Conclusions
First off, Claude has been insanely helpful in building these analytics in such a short time. I've done my best to ensure that the data processing is accurate, but several charts and stats use heuristics or proxies due to missing information. Some charts have Explanation buttons to cover the methodology in more detail - please let me know if I'm wrong somewhere!
Thanks also to shadcn for releasing shadcn/charts just in time to use some awesome charts for this analysis.
Now, the primary takeaway from this test for us has been that the fundamental two premises are sound. Large browser-based networks can exist healthily without being bound by available compute, devices or memory, especially in a setting where the device is being actively used for compute-heavy tasks. Embedding-based consensus is a useful first step to verifiable inference - albeit with a lot more work needed to validate individual scenarios and the security guarantees that can exist in a byzantine environment.
The biggest problem we ran into was that of partitioning. Nodes couldn't always see the same inferences, requests, commits or reveals, and therefore couldn't maintain the same global state. There are a number of fixes for this problem:
- Increased timeouts for each phase of the consensus process should give the network more room to settle.
- Direct p2p connections with participating nodes in each consensus should make transmission more reliable. Currently, every node in the Rakis network shouts to all nodes, and this n^2 communication doesn't scale reliably to high throughput - I'm honestly surprised we got this far.
- (Optional) a third round of consensus where nodes agree to drop commits that they didn't see, or allowing retransmission requests for reveals should bring the commit divergence between nodes a lot closer together.
All things considered, we have enough to consider Rakis a promising stability test.
§Next Steps
The primary intent behind Rakis has been to introduce some new primitives, and run an 'in-the-wild' stability test for permissionless, verifiable AI networks.
The second intent was to get AI inference on-chain as quickly as possible. Our next task is to do exactly this. Ten days ago we pushed the first ever on-chain inference requests from Polygon, Arbitrum and Sepolia to the Rakis network, where it was inferenced successfully by the network.
The plan is to continue this until we have a proper example contract (perhaps an NFT) deployed to each chain, where the mint will rely on Rakis to generate interesting outputs. We can call this phase 2 of the stability test, and likely the participants of phase 1 will be included (at least the chain identities that are known) will be included in this test.
Something we've been meaning to do since the beginning is to allow for structured outputs, and to do more deterministic comparison for those outputs. This is something that we'll leave as a stretch goal for now.
I'd like to thank everyone who was part of ST1. Rakis as always remains running at rakis.ai, the code is on Github, and you can read more about the origins of Rakis here.
The complete set of interactive analytics is live, and the accompanying repo should be available soon.

Not a newsletter





