Building a Rakis
I'm interested in how far Rakis gets before it fails - and why it'll fail.
Can you really run trustless AI inference when large language models tend to be non-deterministic? How useful would it be to add a callLLM function to smart contracts, and to give modern AI agents access to immutability and a payment rail? Can you run an inference network with no servers?
Sometimes the best way to find out is to do it. These have been the questions that have plagued me for the last few weeks, and they've led to Rakis: a decentralized inference network that runs entirely in the browser.
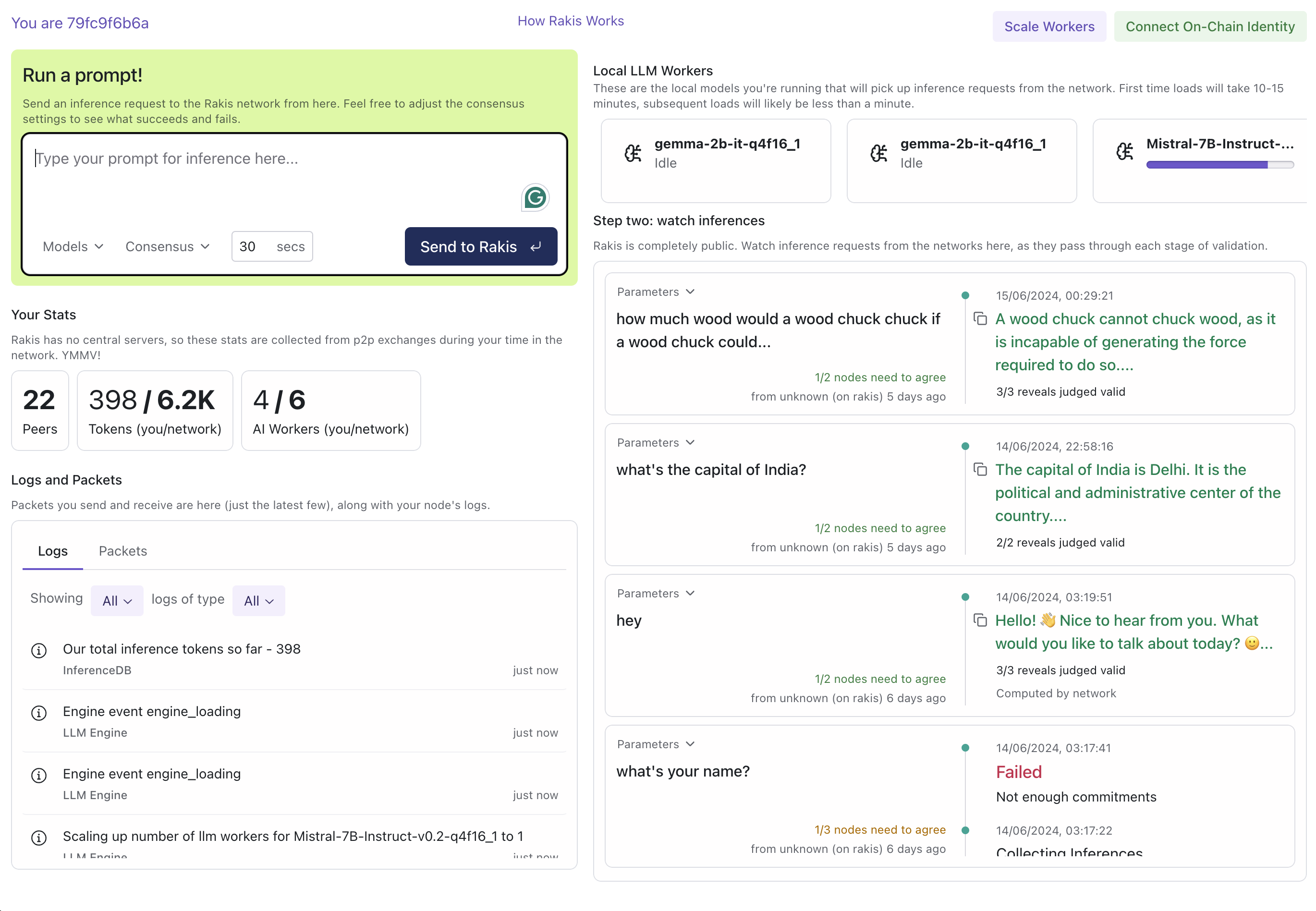
Nodes can pick up inference requests (prompts with adjustable security guarantees) from each other or any blockchain, run inference, embed and hash the results, commit and reveal their results to form quorums, and perform deterministic consensus based on embedding clusters to reach a final output.
You can find out if you go to Rakis.ai (or the open-source versions hosted on Huggingface or IPFS (to be added once we stabilise)) and enter a password. If you're on a WebGPU-compatible platform (like Chrome on laptops or desktops) you can run AI models and provide inference to the network. If not, you can submit inference requests to multiple models, adjust the consensus guarantees and see how it works in action.
Of course, don't run code you can't see. Don't trust, verify. Rakis is open-source from day one, with wonderfully detailed docs provided by Lumie. There are no servers or hidden code - what I'm running is the same as what you are, and it's the same as what's in the repo.
(You can also drop this file into ChatGPT or Claude to ask questions about the inner workings of Rakis - it's a conveniently compressed version of the important bits of the code.)
This post is meant to cover the story of Rakis, the key problems with decentralized inference and how Rakis attempts to solve them. At the end is also a contribution guide for how you can help - and you can.
We'll cover:
- How Rakis came to be
- The current landscape of AIxCrypto
- The big problems we need to solve
- The solutions Rakis proposes
- Unimplemented solutions
- What this release means
- How you can help
§How it happened
Rakis was written by me over a few weeknights. I fully expected to stop long before it was done, but what you can do today on the browser is truly surprising, especially when you're an AI-assisted generalist who knows a little about a bunch.
If you know me you'll believe me when I say this - I was just trying to take a break. Still am - as I write this I'm on a flight headed to Queenstown to spend time with family. But it's hard to give up the coding habit, and it has been a genuinely fun build.
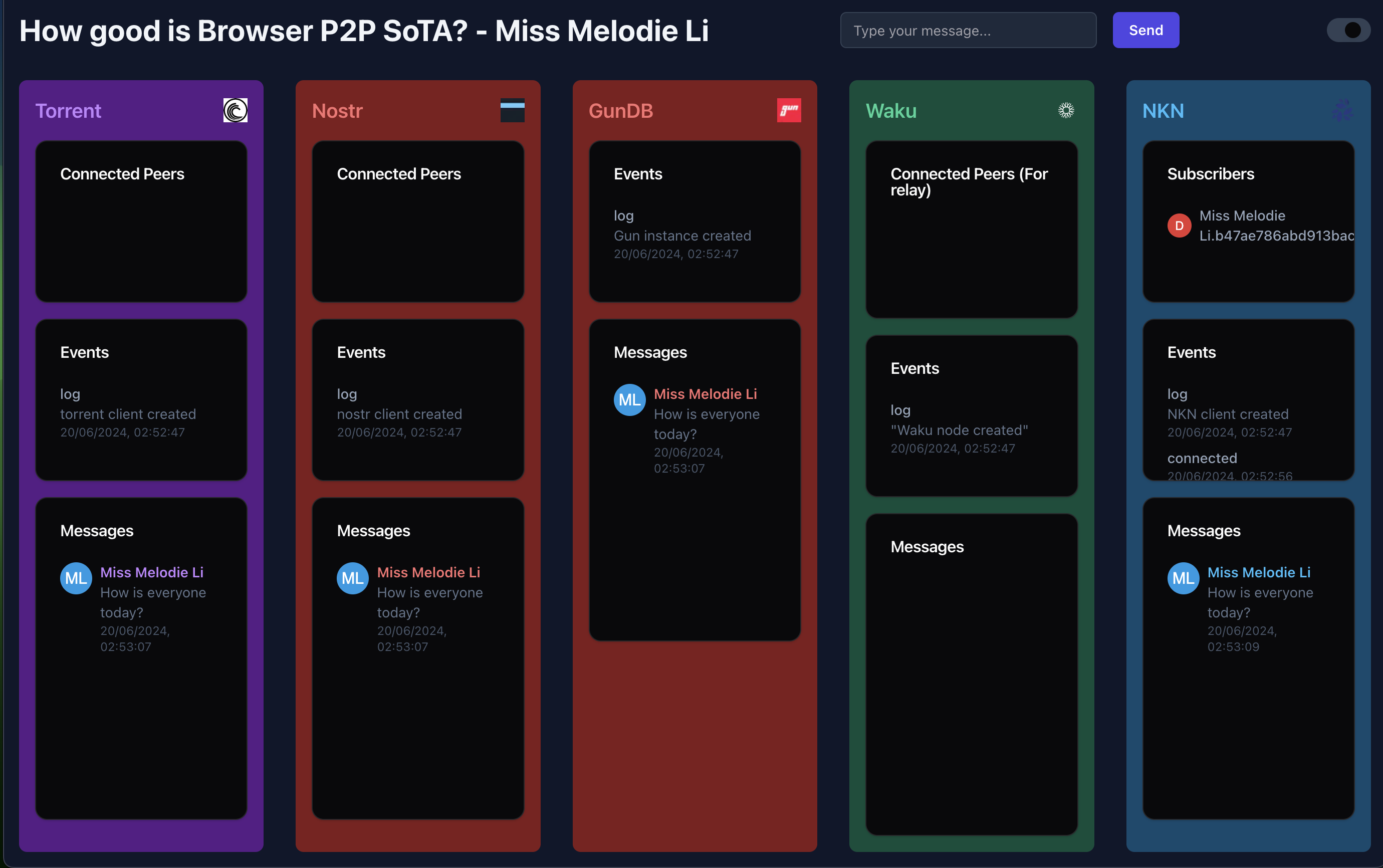
(Except for one piece - despite how long such networks have been around, figuring out peer-to-peer communication has been a massive pain. libp2p-js migrating everything into one repo and Helia migrating out has punched Jupiter-sized holes in documentation across the internet on how to get a basic implementation up and running. Almost everything you land on with the first and second hop is now deprecated and invalid. Oh well. However, PewpewDB, Waku, NKN, and Trystero have been super helpful - with great communities - in getting this off the ground. Special mention to NKN and Trystero for how easy they make first-time setup and pubsub.
I fought this problem long enough that there's a little demo comparing the key P2P delivery networks with a chat app, built right into the Rakis code!)
The concept for Rakis came out of conversations between me and DgtJulian. If you can add a callLLM() instruction to the modern smart contract instruction set, you make two things happen simultaneously:
- On-chain, smart contracts now gain probabilistic computation, advanced NLP, more creativity, and a base unit for general intelligence.
- In the world of AI agents, you give them immutability, disconnect them from their makers, and hand them payment rails.
Imagine self-executing trusts and grants or decentralised claims adjudicators, agents that pay for their API costs, Sybil detection mechanisms that use transaction histories - I think the best applications are the ones I can't think of yet.
Building this project has been my way of proving to myself that the browser is now an accessible full-fledged application platform - even at my level of skill. We'll do a deep dive into the technical architecture in another post, but the sheer number of things working in parallel to run the network is not trivial.
Browsers also have a way of democratizing access - everyone has one, and the variation in client-side compute and size is positively democratic compared to what exists on the server side. Most inference networks I've seen so far have large H100s run by well-funded actors that bully and centralize the whole thing (much like midgame BTC or ETH), and it's harder to do with browsers. Rakis also supports follower nodes, so you can load it on an iPad or a phone, and send inference requests without participating (but we'd appreciate you doing both!)
There's something deeply romantic about a single compiled webpage - much like the early encyclopedias that came in CDs - that can be served statically, saved to your machine, that is yours to inspect and modify, and can't be changed without permission once you have it, and with no other hidden parts.
§The current landscape of AIxCrypto
This is a rather myopic view, having been limited by the time I could spend looking around in between things. Given the rather sinking feeling I had from the time I did spend, I would be happy to be wrong. If I am, please let me know and I'll add it at the end.
As someone who has worked in both the smart contract and AI spaces, I get a number of due diligence requests for AIxCrypto/AIxP2P companies. There are some genuinely good ones out there - but almost all of them have the following properties:
-
They don't have a working, open-source prototype. Huge roadmaps, but nothing real or verifiable.
-
They have no real solution to the fact that language models aren't deterministic. This usually leads to two (or three if you stretch it) possible proposed solutions, none of which are currently reachable:
a. ZKML: You don't need repeatability if you can have cryptographic proof that the single run (which is the only one you have) happened correctly. Unfortunately with the current state of ZK and the sheer size of LLMs, it's unclear how long this will take, especially with AI models not having stabilized yet. Likely a long time, unless we have some massive breakthrough, which is equally likely tonight or next year.
b. TPM: Same as Apple and Samsung's solution to the problem that validating biometrics means storing actual fingerprints, what if we could run the model inside a Trusted Compute Module (like SGX)? Unfortunately these are tiny - like really, really tiny. Unless these projects are proposing building their own ASICs - this is also likely never happening.
c. Something something prediction markets or social voting. There have rarely been cases where this has worked, and if you get it to work you've got a massively valuable distributed RLHF system that's more useful than the actual network.
That said, there are a lot of genuine attempts at defining agentic interfaces for smart contracts, on distributed inference, and in solving other problems. I massively respect the folks pushing ZKML forward, with that recent demo getting us even closer. I still find it hard to respect token raises that depend on some other team pushing ZK forward with no real sign of execution yet.
I'm hoping Rakis is helpful - and that some of the modules, patterns and primitives end up pushing us forward. Even if the core ideas are proven wrong at some point, I'm hoping it functions as a way to coalesce conversations around decentralized AI and inference.
§The problems we need to solve
There are four large problems that any large peer-to-peer inference network will need to solve (or decide to tradeoff).
§Problem 1: AIs play with dice
The biggest problem in p2p inference is that executing large AI models is never deterministic. Given the sheer number of decimal multiplications, multiple runs with the same prompt at temperature zero with the same model can produce different results.
This problem is bad enough that even sentence embeddings aren't usually repeatable exactly.
This is a big issue for peer-to-peer networks, where the traditional method of consensus has been to simply recheck each other's work. If you don't trust a Bitcoin node, you can get the root, the transactions, and simply recompute the tip. Without it, you're left trusting that whoever conducted the inference has been truthful, at which point you might as well trust Sam for better, cheaper, faster results.
§Problem 2: Oracles
The second problem is that a decentralized system can't easily interface with a centralized system, while preserving the same guarantees and lack of trust. This is why oracles are still an open problem with different solutions implying separate tradeoffs. How do you build an oracle for general-purpose text with no simple way to compare things? If you accept that the output isn't deterministic, you still need some deterministic consensus mechanism that can be repeated across the network to produce a final output that can then be pushed back on-chain.
§Problem 3: Incentives, Sybil and freerides
Once you have a network, you run into some causal chains. Inference isn't free - it might be in a boom, but not once the dust settles. Someone had to spend depreciating hardware and electricity to get you your tokens. That means an economic incentive needs to exist, somewhere down the line - for any production inference network.
Once you introduce an incentive - token, cash, etc - your network, whether it was designed to or not - needs to get byzantine tolerant really, really quickly.
Two main problems exist that I can see:
- Sybil - you need some way to prevent one person from pretending to be fifty and collecting 50 payouts.
- Freerides - how do you stop people from copying someone else's homework and collecting a reward?
§Problem 4: Adversarial Machine Learning
This is something Vitalik kindly pointed out some time ago (see AI as rules of the game). He puts it better than I can:
"If an AI model that plays a key role in a mechanism is closed, you can't verify its inner workings, and so it's no better than a centralized application. If the AI model is open, then an attacker can download and simulate it locally, and design heavily optimized attacks to trick the model, which they can then replay on the live network."
Prompt engineering attacks would be a subset of this much larger problem.
§Problem 5: Secure inference
This is another open problem - and definitely out of scope for Rakis, but worth mentioning. Due to the nature of modern AI models, they need plaintext to operate on, which means that your prompt (and information) will need to be completely exposed right before it goes into a model. You can split the model and possibly the prompts, but having only just gotten models to reliably produce intelligence output on plaintext, I'd wager we're pretty far away from them being able to operate on an encrypted space, if ever.
§The solutions Rakis proposes
§Adjustable security bindings
Rakis implements an embedding-based consensus mechanism with a commit-reveal system. On-chain contracts (like this one) or peers in the network fire off inference requests, which specify the parameters (prompt, temperature, etc) and a security frame.
The security frame is intended to make consensus looser or tighter so that applications with higher security (and determinism) needs can spend more for more redundant compute, while other dApps with simpler needs (write me the next chapter of this NFT) can choose faster, cheaper methods.
Here's how things work:
Inference requests are picked up by nodes on the network (the browser tabs, of which you're hopefully now one) and executed when they can. Requests expire after a certain time period, at which point the security frame is used to figure out if we can run consensus. The Security Frame has the following adjustable parameters:
- The Quorum Size: How many different nodes need to run this inference within the time for it to be valid?
- SecDistance: How similar do the results need to be? We define this as a distance.
- SecPercentage: What percentage of the participants need to be within this distance? How many outliers/bad actors can we tolerate?
For example, a simple creative project that attempts to write a custom story based on a user's transaction history or a smart contract that merges two game cards together to get new traits might specify a lower quorum size, a wider SecDistance, and a lower SecPercentage. A financial project that evaluates incoming grant proposals or parses PDFs would do the opposite.
During the time allotted for inference, participants exchange hashes that irreversibly represent their results. This is known as a commit and locks them into a certain result without being able to copy anyone else's.
When this time ends, if there are enough commits, nodes form a quorum, and request a reveal. Once all outputs are revealed, they're verified to the commit, and consensus starts.
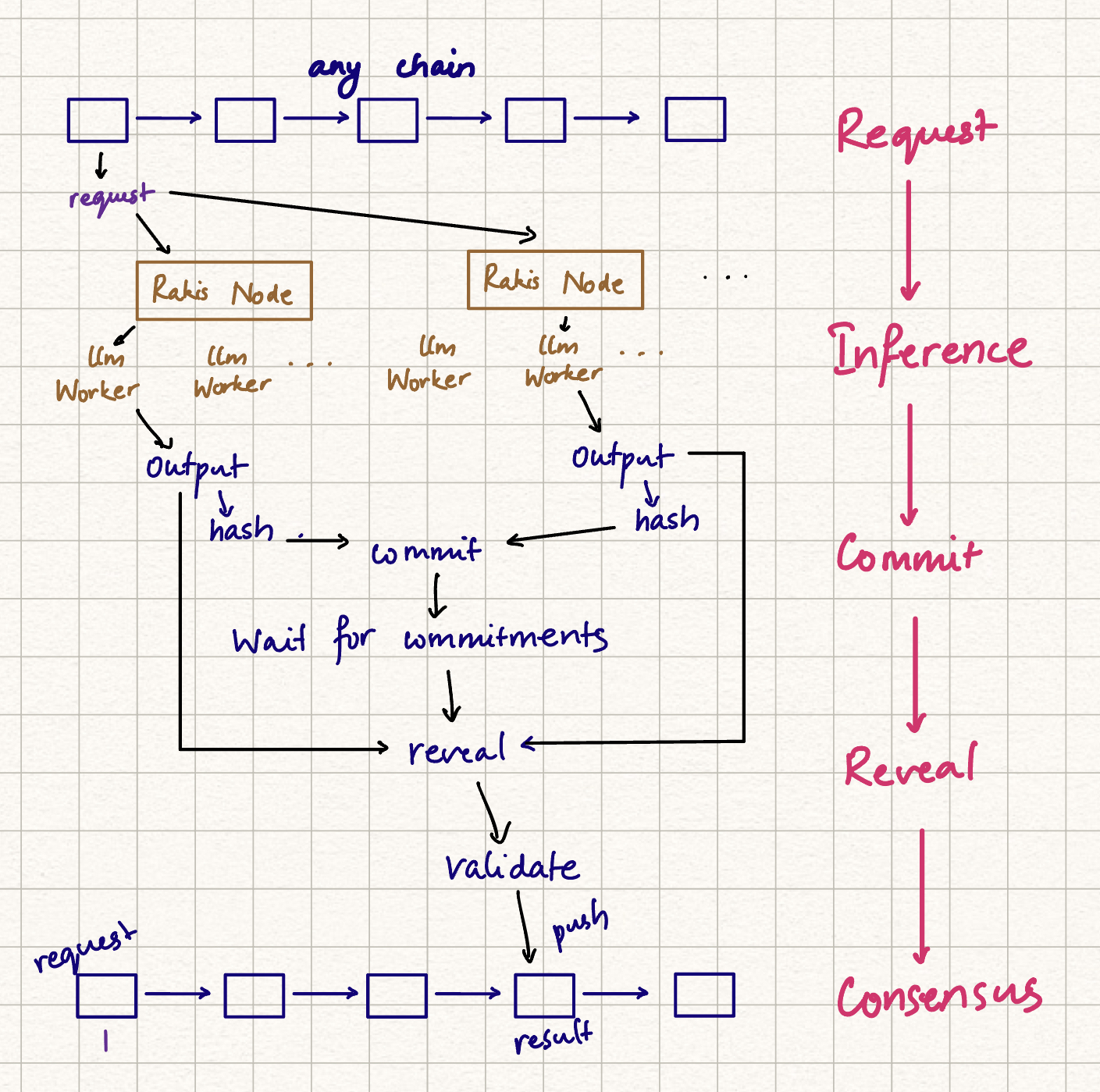
The implemented consensus mechanism is simple. The outputs are embedded (with the use of binary embeddings (which I first learned about from Simon through Joseph) which have proved relatively deterministic in our tests), and the embedding clusters are used as measure of agreement. We try to find the location of a sphere of radius SecDistance that has the highest number of points, in high dimensional embedding space. Inference outputs outside this sphere are considered failing, and the rest are deterministically hashed for a source of randomness to select one.
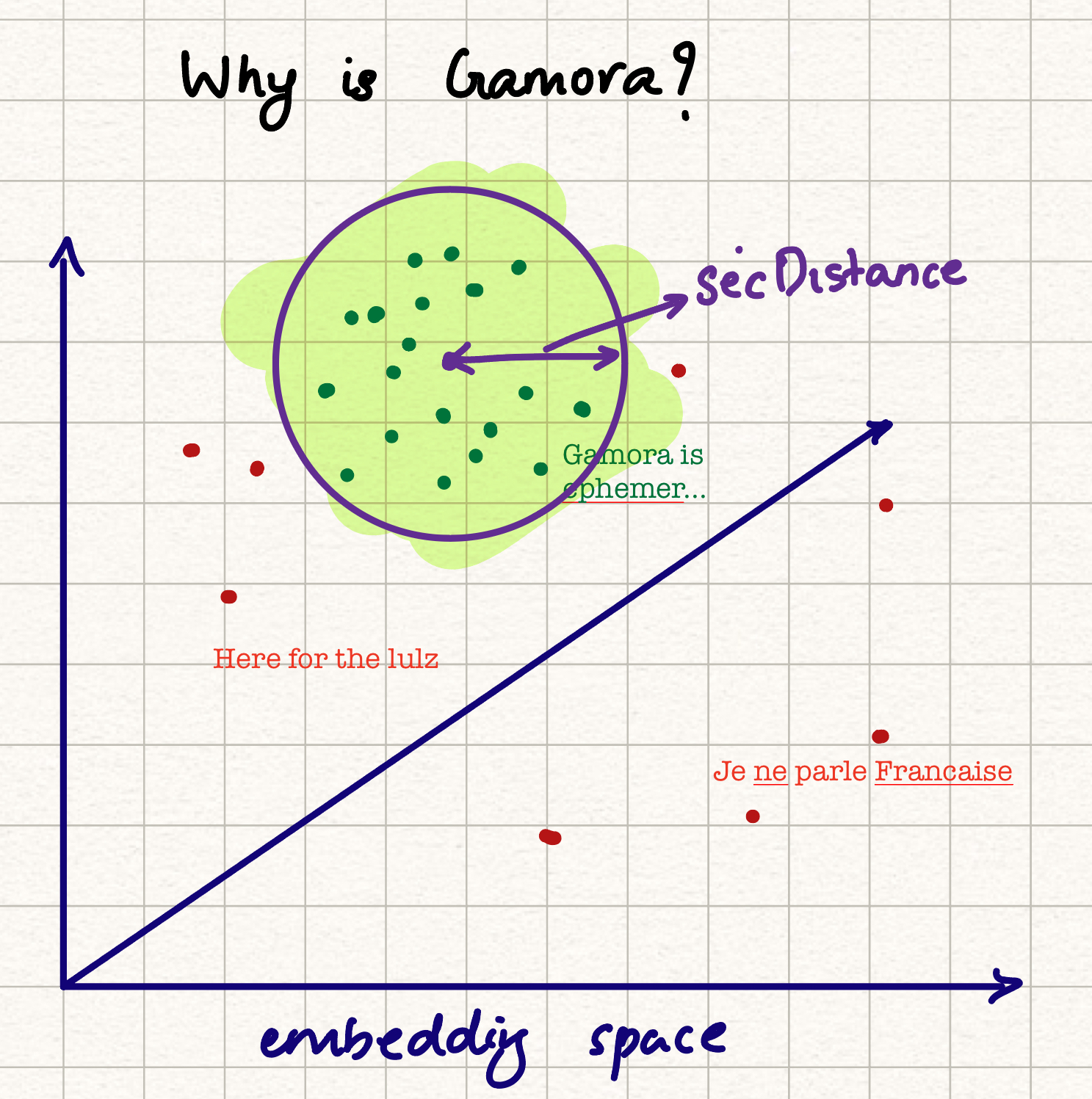
We make use of Matryoshka Embeddings to be able to adjust the determinism for embeddings in the future. Based on the output of the stability test, we'll either fix the number of bits used, or make it adjustable by either the network or the inference requester.
This is a quick demo that's built into Rakis for you to test this hypothesis. It's a little rough around the edges, but you can run different models and prompts, and check the embedding cluster graph at the bottom to see if clusters work as a method of consensus.
This is simple - and extensible. You can see the code (along with commented links to other methods for clustering) here. Here are some possible upgrades and replacements to the consensus mechanism we could implement:
- Improved clustering algorithms that extend the consensus window or reduce it depending on the application.
- Adding JSON mode and the ability to compare semi-structured output for consensus. Could we compare fixed fields (like booleans and numbers) exactly, and leave the fuzzy matching to string fields? This should be relatively simple to implement. Adding jsonschema for constrained output to the inference requests would also be useful.
- Requesting multiple embedding models - see the section on Heterogeneity is a strength for why multiple models on the same request can be useful.
- Small models as evaluators - the original discussion about this project had the idea of using tiny, tiny models (1.5B-2B) with constrained output as a way to get deterministic comparisons, which could then be MapReduced down to do consensus on larger lists of outputs. The core idea was that you use small models and ask them to decide if the outputs of large models were in agreement. Tiny models can be made (relatively) deterministic, but this is still untested and might increase the adversarial machine learning attack surface.
§An oracle for embeddable data
If the consensus mechanism(s) we've described work, they open the door for more 'fuzzy' data to be introduced via oracle mechanisms. If you can compare, cluster and validate different LLM outputs, you can also look for agreement in news reports, pdfs, earnings call transcripts, etc - and bring them deterministically on-chain for contracts to use directly.
Here's something else we can do (that was almost a functioning part of the codebase): if you have a decentralised oracle, you can trustlessly add in centralised models. What if nodes plugged in an OpenAI or Anthropic key, and on-chain smart contracts could call the absolute best models humanity has developed? Barring the problem of transaction replayability in the future (due to deprecated models), this might be a good idea. I'm still on the fence as to whether we gain more than we lose here - leaning for rather than against tonight.
§Different is good
Vitalik (and others) are right to point out that prompt-engineering and other counter-ML attacks are viable surfaces, that will start being used as soon as its economically useful to do so. Chevy's customer service bot is a good early dumb example.
However, if you have a method of consensus that actually favors non-determinism (and later we'll see if we can reward it), there's a partial solution: run the same problem on different models, of different architectures and sizes.
The more models and families you involve, the larger potential attacks need to be in order to reliably affect the output. If consensus works, unduly influenced models (if they're in the minority) should get voted out - at least that's the thesis.
In simple terms: Being able to run more copies of the same inference on a large number of models should make attacks harder.
Now about the things I couldn't realistically get to in ten days:
§Unimplemented solutions
§Sybil
The simple way to solve Sybil here is to run validator nodes - like (sigh) Hyperledger. Known large organizations (like the Solana and Ethereum foundations) can run nodes that validate outputs by rerunning inferences. This would work, but it would impose an upper cap on the throughput of the network (what the validator nodes could validate in reasonable time) and give up some of the guarantees of decentralization we could get.
An untested solution (which could use its own post) is to take advantage of heterogeneity. This is hard to explain in a single paragraph, but there might be functions that reward a difference in output - in embedding space, it is mathematically possible to say that your reward for an inference should be proportional to how dissimilar your output was to everyone else's, while still being within the valid cluster. I think it should also be possible (again, untested) to then adjust those incentives such that copying your output 20 times nets you the same amount as submitting it once.
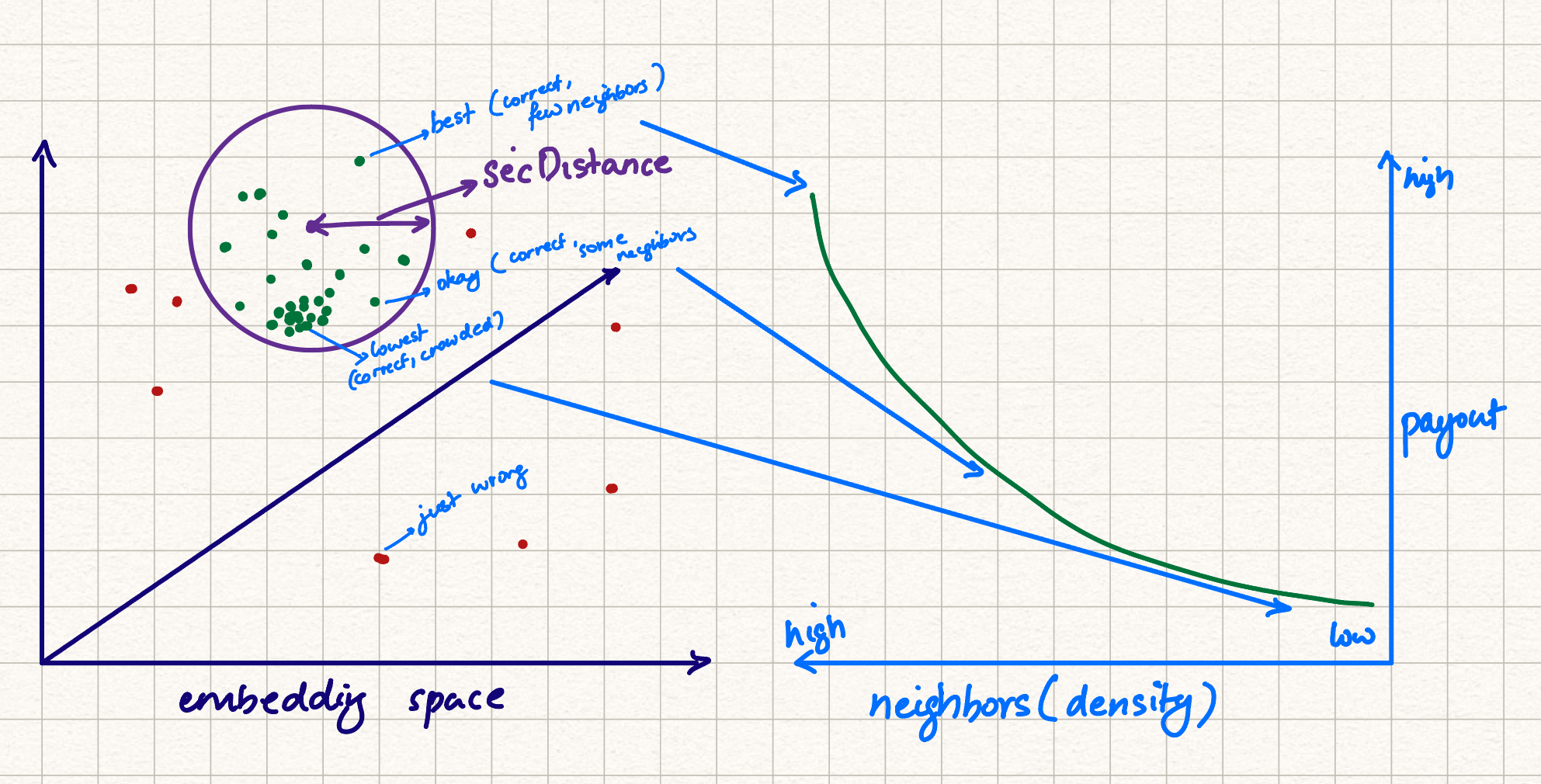
A third solution would be to double-check inference results by partitioning the network and checking some percentage of transactions against other clusters. In simple terms, you would split the network into groups (using deterministic random selection or other methods), and have one group's output rechecked by another group, with some amount of reputation/slashing built in.
Straight up staking and slashing is unlikely to work - at least how I've seen it often implemented. Prevention is always better than curing things after the fact, and I've always thought that staking works rarely - and even when it does it simply puts an economic price on bad behavior, much like a speeding ticket. If you end up connecting your system to things that far outweigh what you can penalize someone for, you're almost asking them to take advantage of that arbitrage in stakes.
I'm hoping to find some time later on to implement some of these solutions and add them to the stability test, as a way to see which ones actually hold water. I'm definitely open to suggestions here.
§What this release means
So, why release it? I usually build things because they won't leave me alone until they take some kind of form. In this case, nothing I've said above is a certainty - this is all conjecture. Byzantine environments are hell for the best-made plans - and there's no real alternative to a field test. With large decentralized consensus mechanisms, fail often, fail early is the right way to go.
Additionally, there's a discord - and I'm hoping it (or something like it somewhere) becomes a lightning rod for the singular conversation of permissionless decentralized inference for smart contracts. If one of us can get it to work, I think this new instruction set of prompting can actually, finally realize the vision that once existed about self-executing code and governance.
If that doesn't happen, maybe it could be a conversation spot to discuss inference in the browser. This is still pretty slept on - the future I think has orders of magnitude more AIs functioning completely in the browser, and I'd like to find more people that thought keeps up at night.
§How you can help
For one, use it! Tell me what you think on Twitter. You can also help the project by adding a star, or a PR for any of the big or small TODOs.
Rakis is also pretty extensible - and intentionally built on a layered architecture. We already use five different P2P networks for redundant message delivery (more on the architecture in another post), so it's easy to add more networks, more chains, more contract specs, more models and execution engines, more support for more things!
You can also very easily fork the Rakis network. If you change the topics that Rakis communicates in, you'll effectively have your own private Rakis network. Only people with your network name can find your peers, and you guys can have your own little party in there.
§What I'm doing now
I'm - um - spending time with family in New Zealand for a few weeks. Code - and everything else we have - should serve people - and so should I, especially people close to me. Prepare for me to be a little slow responding if this article isn't more than 3 weeks old when you find it - but you can also reach out to DgtJulian who has kindly agreed to help even more than he already has.
§Thanks
Thanking all the giants whose shoulders this work is built on deserves an entire post, but I'll summarise here. Without the amazing work of xenova and the mlc-llm team, browser-based inference would be a pipe dream. Peer-to-peer communications are still not an easy thing to do - especially without running servers. Hats off to all the people behind the technology stack that has matured enough to make this possible, from WebRTC, the people at libp2p, nkn, pewpew (avoiding the scunthorpe problem), waku and so many more I’ll thank as I get around to writing the technical piece.

Not a newsletter





