Good-enough-compression for shipping routes
Pretend we have 10 GB of timestamped positions of ships all over the water, and we would like that to be smaller. Now pretend I have one day to get something done and up so we don't run out of space. How small could we make it?

Welcome to the world of timeseries compression, with custom specs!
§Lots of coordinates, so little space
We store a lot of information around the positions of ships, the most basic form of which is a tuple of latitude, longitude, and time. Put these together into an array, and you have routes like these:
Interspersed within these routes are events that a vessel undergoes, like a port call. Holding on to past information of this kind is useful , both for specific vessels, and in the aggregate - like fleets or the entire world of maritime. In the specific, knowing what a vessel has been upto can be useful for computing corporate tax liabilities, risk compensation, etc. It's also useful in the aggregate, this data can be used to predict emerging maritime routes, point out congestion and wait times.
How do we store and retrieve this data?
We started out by stuffing it into a postgres table (as one does) with basic indexing - no partitions, no cold storage. This worked for a while - and it still does - but we will run into problems soon enough if we don't find a better solution.
Optimizing postgres for data that needs much faster access is a post on its own, and I'll likely combine it with a similar problem we face with storing flight data for another time.
We can take a lot of the more complex data that we need to aggregate often, like metadata and events, and keep them in postgres for now. The position information is what takes up 98% of our space.
We can start by writing these to json files, and this is where we get our 10 gigs from. Before we compress it, let's look at our constraints.
§Custom specs
Here's what we would need out of our storage and compression system:
- We want to be able to access sequential pieces of a single vessel's history, i.e. What was the ATHENA HORIZON doing from 06-06-2021 to 08-08-2021?
- We are okay with spending more time for aggregate queries on this data - taking seconds or minutes is perfectly fine.
- We'd like to preserve as much of the information (that we care about) as we can.
- We want the encoding to have good support across languages if possible to save time later on (see point 6).
- Ideally, we want to compress a set of information without needing to hold all of it in memory.
- We'd like to build and implement this system in a day or so of work.
- We can take another day to write this post.
Sorry for burying the lede - number six is absolutely the limiting factor in what our solution looks like, but in a startup them's the breaks.
§Don't build what you can plagiarise
As with everything in software, we want to learn from what we can find. Looking at prior art, two main methods emerge.
§Simplifying geographic data
This class of solutions try to eliminate points that aren't adding much complexity to a series of coordinates. turf/simplify is a solid implementation of the Ramer–Douglas–Peucker algorithm to encode a polyline into a simpler shape. RDP lets you define a general bound on global complexity, while other solutions try to remove points with a more local focus.
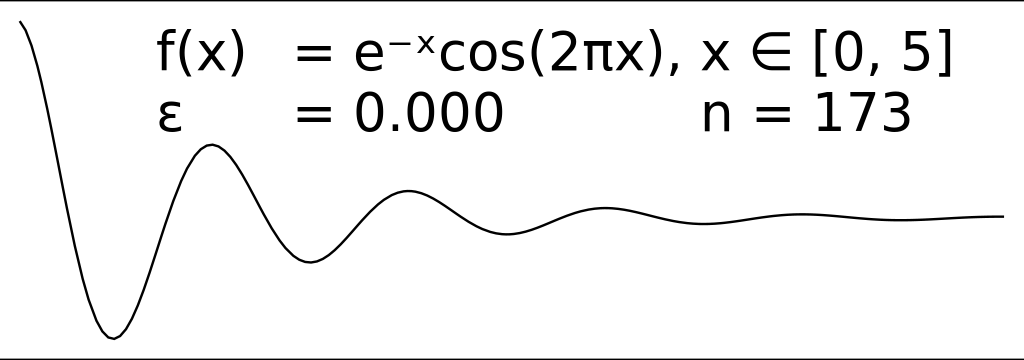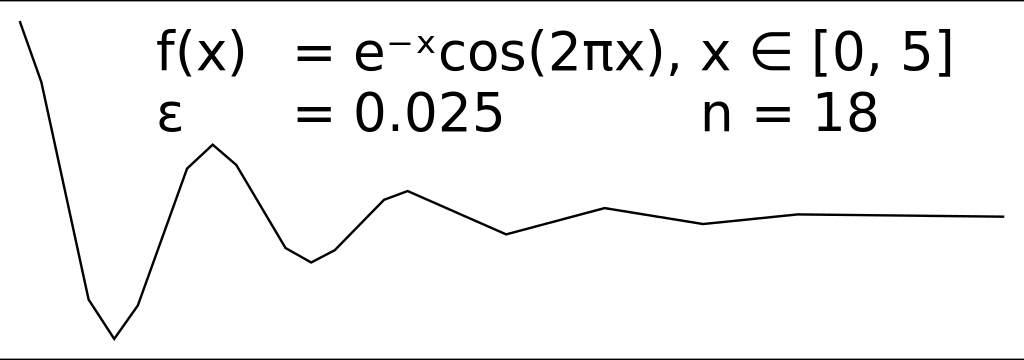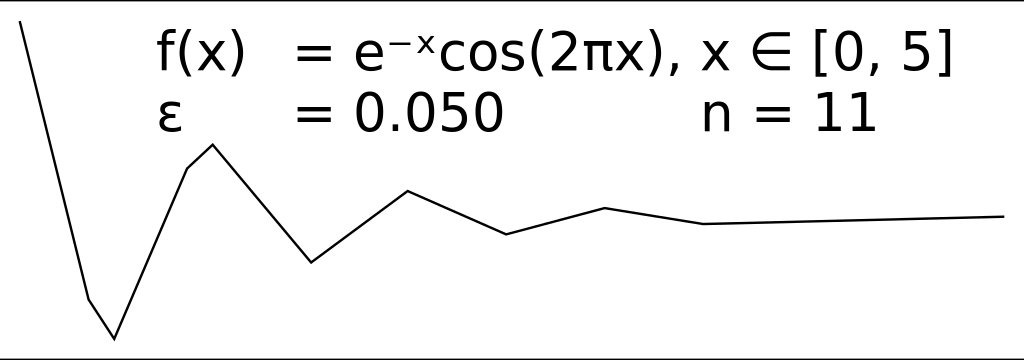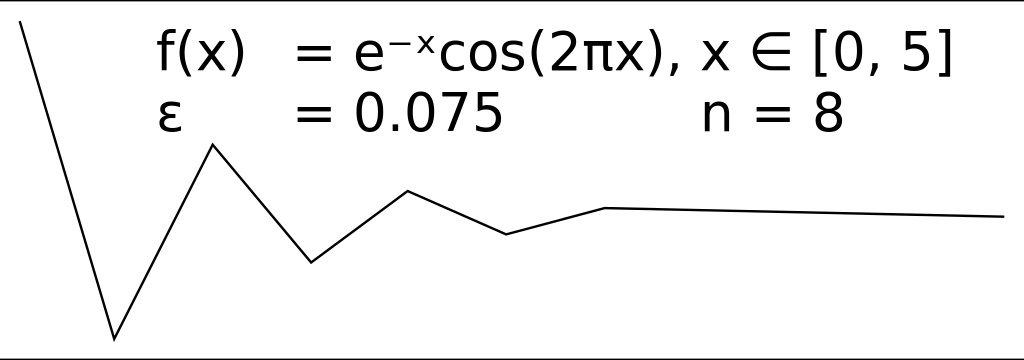
We are happy users of turf/simplify in our code to reduce the size of predicted routes, generated by our maritime routing engine. However, historical data contains timestamps, which makes it significantly more complex to simplify a polyline while maintaining time information relating to vessel activity. It is definitely possible to find a solution that can work well with stops, patrols and other patterns observed at sea, but we might not have the time to build and implement one ourselves.
Additionally, polyline compression usually functions better with more information in memory, which will be hard to accomodate well. Let's try something else.
§Binary Representations
This class of methods often attempt to find the most efficient bitwise storage method for geographic data([1],[2]). One set of suggested solutions involves finding the appropriate number of bytes to store coordinate data, and the use of varints (which sacrifice some low amount of per-byte space to store largely varying integers more efficiently) to reduce the space needed for each coordinate even further. The second is around storing deltas (or changes from previous value, known as delta encoding) instead of the full value across the path - this significantly reduces the space requirement for subsequent packets, and is a much, much simpler form of the same keyframe compression used in h264 or avc.
Delta of delta encoding is a useful way to further compress delta encoded data if it follows regular intervals. Unfortunately this is not true of our data - vessels send [AIS] updates on a regular basis, but varying satellite visibility and weather patterns mean that the received information is often irregular.
Google's encoded polyline format is a wonderful method for simplifying data into a format that can still be parsed as characters, while maintaining acceptable resolution.
Tiny Well Known Binary is a format that I've seen suggested, but without much support outside of .NET (from my research), it's not very useful to us. Time to implementation with TWKB might be about the same as us writing our own implementation.
(Additional reading here might be Simple-8b compression or other dictionary compression techniques. Interestingly, tokenisation on modern llms follows similar compression techniques.)
§Good-Enough-Compression and retrieval
In this post, we go over the details of implementing GEC, a new compression format that blends our specifications with the limited time of an overworked CTO.
To begin with, we need a place to store our information. We'll start with one of the most obvious places - in the filesystem. If we have large data that we want to easily back up or inspect, simply storing it in the filesystem is often worth considering. Some advantages of using the filesystem include:
- Slow moving, stable standards - using files and folders inside modern filesystems usually has amazing support across everything, and the APIs are unlikely to change on you.
- Cheap - getting reliable, fast storage is cheap these days.
- Secure - securing filesystems and connected drives is often easier than doing so with more complex systems.
- Tooling - if you're working with a chunk of information, the entire unix toolkit is now easily available for you to use, for compression, stream operations and so on.
Unfortunately what you trade in ease of use and complexity you lose in fine-grained control. File systems are pretty hard to store custom queried metadata in, as well as enforcing specific atomic operations, field-level security, and so on.
For our usecase, this is good for now - at least it's a good place to start. We'll break the paths down based on some key vessel information - like MMSI - but other than that it will be one file per ship (or MMSI).
§Big, ugly JSON
Don't get me wrong - I love JSON. Having something that is easily human-readable has saved more time and money when building a product than we've lost in bandwidth or speed. However, it's also one of the most inefficient ways to store information - especially when it's numeric or floating-point in nature. '123' is three times as big as 123, or even more depending on the platform you're in - and this isn't counting the syntactic characters inside the file. We want something that can handle variable length integers, good typing, and has decent support across the board.
We currently hold our data in newline-delimited json, where we simply append a new packet every time we get a position update to a file. This is what our data looks like, exported from its previous home in a table in Postgres:
{"mmsi":100902340,"lng":119.59518833333333,"lat":35.45740833333333,"course":360,"heading":511,"accuracy":1,"ais_type":"terrestrial","ais_updated_at":"2023-02-20T07:05:45.000Z","created_at":"2023-02-27T07:11:38.220Z"}
{"mmsi":100902340,"lng":119.59521666666666,"lat":35.45739666666667,"course":360,"heading":511,"accuracy":1,"ais_type":"terrestrial","ais_updated_at":"2023-02-20T13:05:18.000Z","created_at":"2023-02-27T07:20:50.392Z"}
We can encode this information into protocol buffers, which has good support in JS as well as supporting varints and type definitions. We will likely also be able to use it across networks, should we decide to build a decompressor into any frontend accessing it.
The first thing we'll do is to process our big ugly packets - which are in the exact same format we got them from our provider - into something smaller and easier to move around.
function simplifyRoutePacket(routePacket) {
return {
latitude: routePacket.lat,
longitude: routePacket.lng,
course: routePacket.course,
heading: routePacket.heading,
terrestrial: routePacket.ais_type === 'terrestrial',
posTimestamp: routePacket.ais_updated_at && new Date(routePacket.ais_updated_at) ? new Date(routePacket.ais_updated_at).getTime() : 0
};
}
Next, we can batch some fixed number of packets into a single protobuf message, and binary encode it:
...
const lines = new LineByLine(infile);
...
const simplifiedRoutePacket = isRoutePacket(packet) ? simplifyRoutePacket(packet) : null;
...
routeData.push(simplifiedRoutePacket);
...
if(isVesselInfoPacket(packet) || routeData.length > MAX_ROUTE_PROTOBUF_SIZE) {
// Vessel has changed particulars (or we've hit maximum proto packet size), flush route and write this packet afterwards.
const compressedRoute64 = await getCompressedRoute(routeData);
}
In getCompressedRoute, we compress the packets using a .proto type definition, and encode them in base64. ChatGPT was very useful in getting to a type definition quickly:
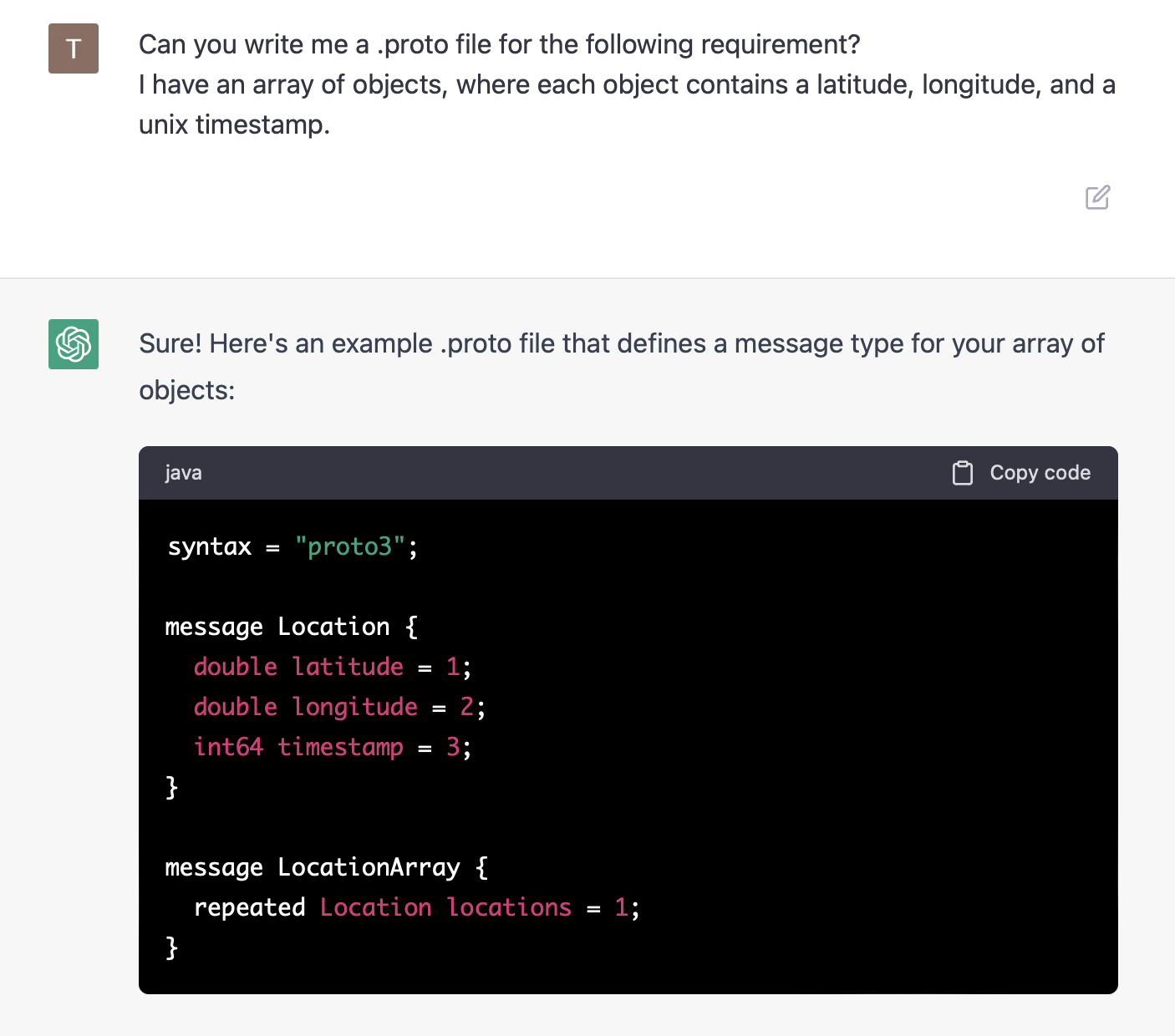
Unfortunately, it's only good if you know how to check your work. I've found that ChatGPT is an accelerant when I already know how to check the answer - and quite scary when it's something completely new to me. In our case, we can do some further questioning:
Let's add a few more fields in, and live with the precision we get from using floats:
package vesselRoute;
syntax = "proto3";
message Point {
required float latitude = 1;
required float longitude = 2;
required float course = 3;
required uint64 posTimestamp = 4;
optional int32 heading = 6;
required bool terrestrial = 7;
}
message Route {
repeated Point points = 1;
}
This is where we make the questionable decision to chunk position updates into fixed length packets, base64 encode them and put them back in as a JSON (WHAT) packet into our file:
{"pbufRt":"ChsNDjxgQhXvjoNBHc1McEMg4Lvci+IwMPABOAEKGw1LNGBCFVlgg0EdzUxvQyCo6+6L4jAw8QE4AQobDbEsYEIVETKDQR2amW9DIKCLgYziMDDwATgBChsNAiVgQhWcA4NBHZqZb0Mg0MKTjOIwMPEBOAEKGw1aHWBCFUTWgkEdzcxuQyDg2qWM4jAw8QE4AQobDasVYEIViqiCQR3NTG9DIJCSuIziMDDyATgBChsNCg5gQhUXe4JBHWbmbkMg8LnKjOIwMPEBOAEKGw19BmBCFdtNgkEdMzNvQyDo2dyM4jAw8gE4AQobDfz+X0IVCiCCQR0AAHBDIMiB74ziMDDxATgBChsNh/dfQhVR8oFBHZoZcEMgqKmBjeIwMPIBOAEKGw31719CFdDEgUEdmhlvQyCP5JON4jAw8QE4AQobDVHoX0IV/peBQR3NzG5DIOj4pY3iMDDxATgBChsN6eBfQhXQaoFBHc3McEMgyKC4jeIwMPEBOAEKGw2y2V9CFec8gUEdzcxwQyCoyMqN4jAw8QE4AQobDX7SX0IVQQ+BQR2aGXFDIKDo3I3iMDDxATgBChsNQMtfQhVl4YBBHZoZcUMg6JfvjeIwMPIBOAEKGw3ow19CFV20gEEdZmZwQyCwx4GO4jAw8wE4AQobDdG8X0IVf4eAQR2amXBDIKjnk47iMDDzATgBChsNvbVfQhUXWoBBHQCAcUMgiI+mjuIwMPMBOAEKGw3Hrl9CFSAsgEEdAIByQyDotriO4jAw8wE4AQobDd+nX0IV+f1/QR0zs3BDIODWyo7iMDDzATgBChsNxKBfQhUSpH9BHc3McEMgwP7cjuIwMPMBOAEKGw1/mV9CFcdJf0EdAIBvQyCIru+O4jAw8QE4AQobDbuRX0IVq+x+QR2aGW9DIOS3go/iMDDxATgBChsNbopfQhWAlH5BHc1Mb0MggJWUj+IwMPABOAEKGw3hgl9CFZ47fkEdzcxuQyCopaaP4jAw8AE4AQobDSR7X0IVZ+N9QR0AAG5DIIjNuI/iMDDwATgBChsNfXNfQhWGi31BHQAAb0Mg6PTKj+IwMPABOAEKGw3Ja19CFS0yfUEdM7NuQyCAtN2P4jAw8AE4AQobDUFkX0IVQdt8QR0AgG5DIKjE74/iMDDwATgBChsNylxfQhXBg3xBHWbmbkMgiOyBkOIwMPABOAEKGw1ZVV9CFUgtfEEdAIBuQyDok5SQ4jAw8AE4AQobDadNX0IVtdZ7QR1m5m1DIIDTppDiMDDwATgBChsNxUVfQhVjfXtBHZqZbUMg4Pq4kOIwMPABOAEKGw35PV9CFZ4ke0EdzUxuQyCIi8uQ4jAw8AE4AQobDS42X0IVVMp6QR3NzG5DIOiy3ZDiMDDxATgBChsNhC5fQhVnbnpBHc1McEMgyNrvkOIwMPEBOAEKGw0TJ19CFTASekEdAABwQyCogoKR4jAw8gE4AQobDaYfX0IVDLZ5QR2amW9DIPCxlJHiMDDxATgBChsNMRhfQhUOW3lBHZoZb0Mg6NGmkeIwMPABOAEKGg3Tv3FCFeWysUEdAAAAACDUpvSB5zAwEjgBChoNz79xQhXnsrFBHQAAAAAgmZjBgucwMBI4AQoaDd+/cUIVvLKxQR0AAAAAINHQmoznMDASOAEKGg3rv3FCFfuysUEdAAAAACD8xeeM5zAwEjgBChoN379xQhXXsrFBHQAAAAAgybepjecwMBI4AQoaDdq/cUIV17KxQR0AAAAAIKa04I3nMDASOAEKGg3bv3FCFQGzsUEdAAAAACCwq62O5zAwEjgBChoN3b9xQhW/srFBHQAAAAAg1qTkjucwMBI4AQoaDdu/cUIV87KxQR0AAAAAINqdm4/nMDASOAEKGg3gv3FCFfaysUEdAAAAACD4gt2P5zAwEjgBChoN1b9xQhXLsrFBHQAAAAAg+4afkOcwMBI4AQ==","earliest":1675598700000,"latest":1676950356859}
{"latitude":60.437345,"longitude":22.212366666666664,"course":0,"heading":18,"terrestrial":true,"posTimestamp":1676950535552}
{"latitude":60.43733333333333,"longitude":22.212308333333333,"course":0,"heading":18,"terrestrial":true,"posTimestamp":1676951436736}
The big benefit here is that we can let updates build up in the same files we already have - thereby keeping our existing toolchain mostly the same. We can also encode things like the earliest and latest tiemstamps inside the packet, so we know if want to unpack it at all. It's a little wasteful, but it gives us a good starting point to start iteratively optimizing.
§Packets for ants
§Round 1 - chunked binary
Trying to compress our 63,841 files at once causes the whole system to freeze up, since all these jobs start at the same time. Let's plug in a simple job queue to limit the number of concurrent jobs. ChatGPT?
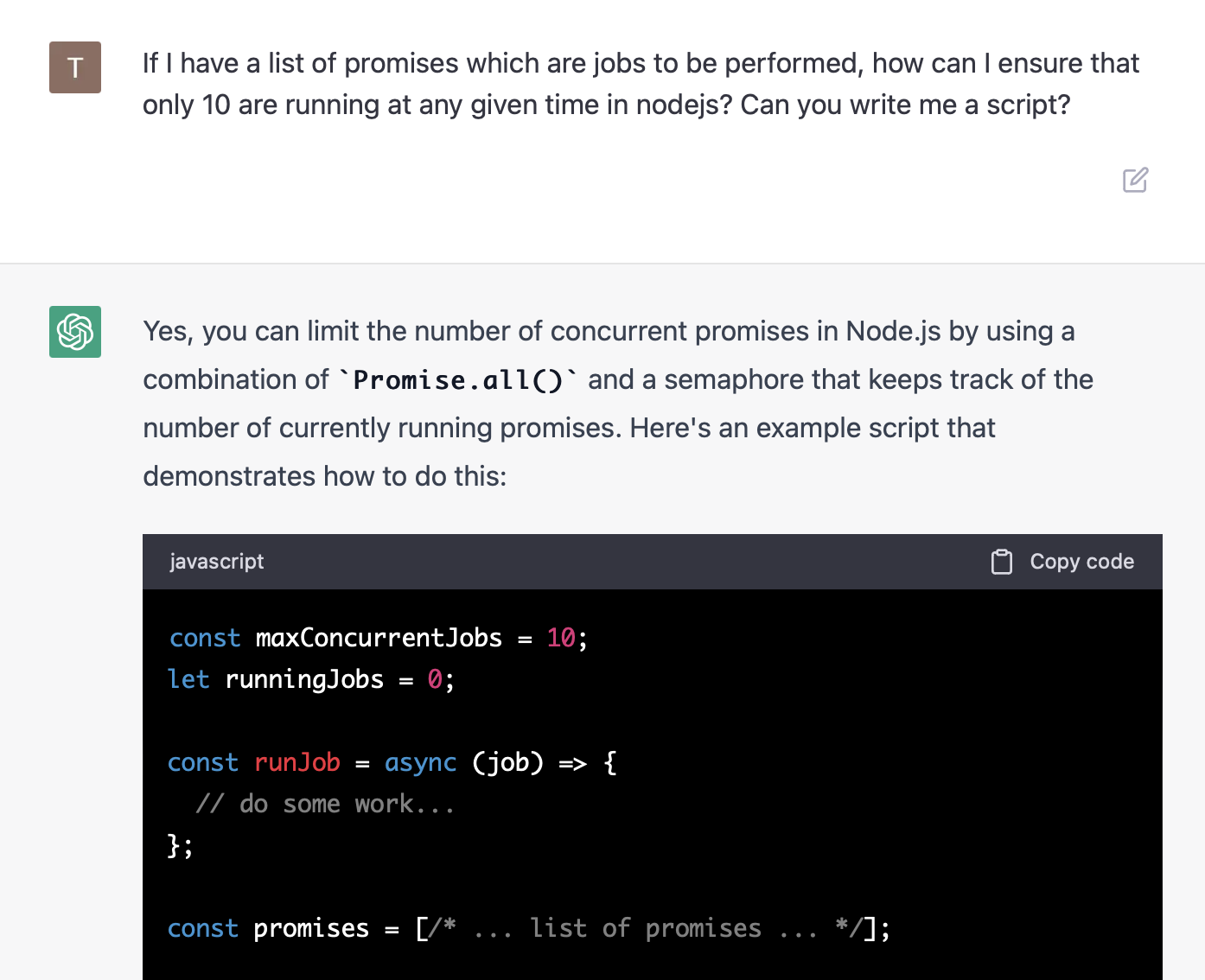
Unfortunately this does it in batches (naive approach), which means we've only set an upper bound on running jobs. To be fair that's what we asked. Let's try again.
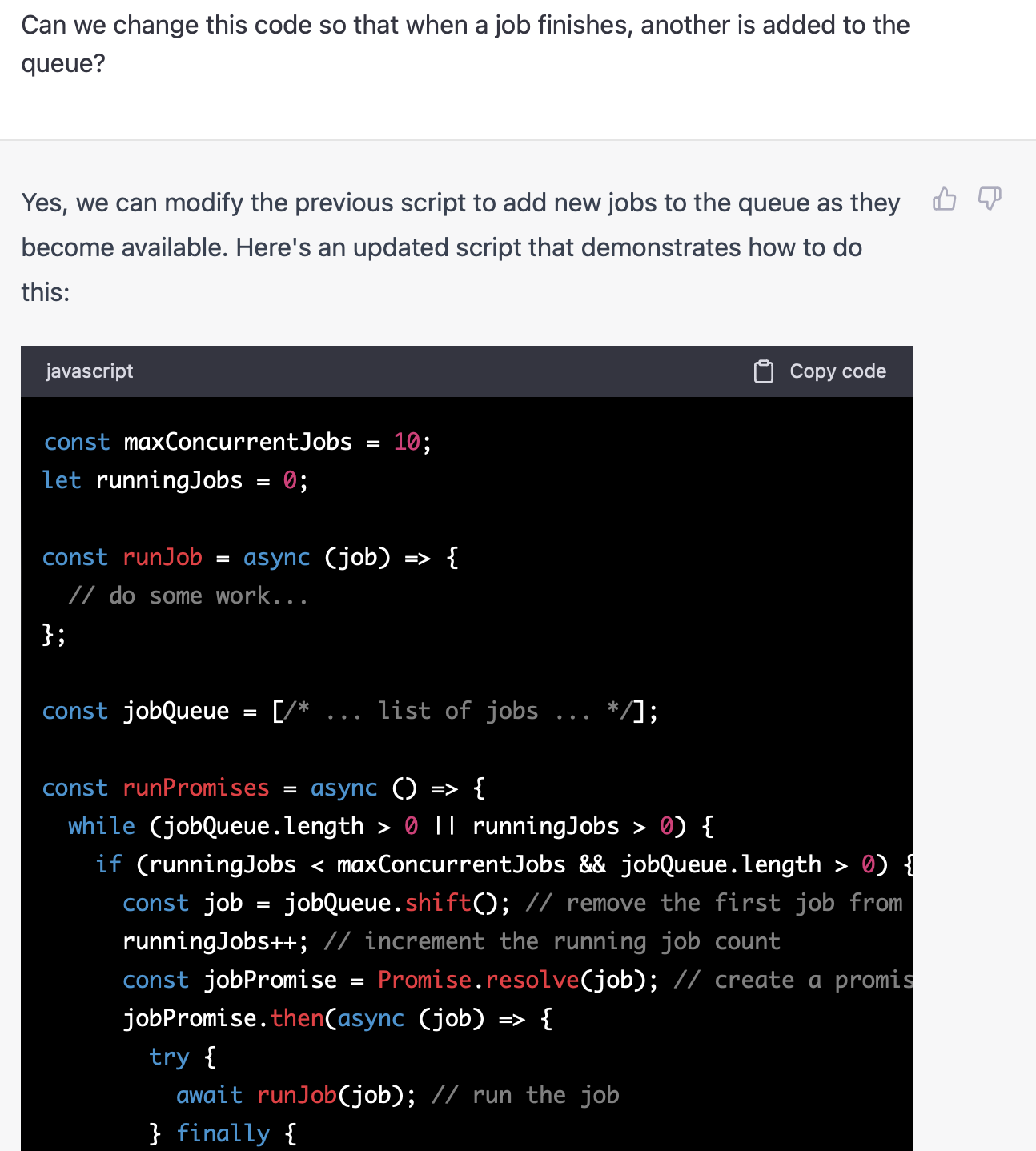
Not too bad!
We'll write our own implementation, but this is quite useful - and ChatGPT is proving to be impressive.
Running with different job sizes shows us that on my hardware, it maxes out around 200 files per second (progressbars to the rescue!). This is pretty variable and dependent on the size of the file but a good rule of thumb. Let's set our job limit to 250 and requeue 10 times a second.
Packet size of 50:
Compressing (packet size 50 ) 100 files from ./positions to ./compressed
Compressing [====================================================================================================] 100% 100/100 0.0/0.5
Compressed 100 files from 17.56 KB to 3.43 KB in 0.692138584 seconds
done
That's pretty good compression! One might even say, good enough? We still have a lot of the day left so let's go a bit further.
(Sidenote: For some reason, we're using the efficiency cores instead of the performance cores on my M1. Doesn't matter much since we'll be running this on a server eventually. As long the behavior stays relatively the same across comparisons we'll have the results we need.)
Compressing everything we have:
Compressing (packet size 50 ) 63841 files from ./positions to ./compressed
Compressing [=====================================================================================================] 100% 63841/63841 250
Compressed 63841 files from 8.97 GB to 1.78 GB in 256582.368292 seconds
we get a compression ratio of about 5x.
Now let's try a bigger packet size of 500, and a smaller packet size of 5.
Compressing (packet size 5 ) 63841 files from ./positions to ./compressed_5
Compressing [=====================================================================================================] 100% 63841/63841 143
Compressed 63841 files from 8.97 GB to 1.41 GB in 7 minutes 27.004025833000014 seconds
Compressing (packet size 50 ) 63841 files from ./positions to ./compressed_50
Compressing [=====================================================================================================] 100% 63841/63841 240
Compressed 63841 files from 8.97 GB to 1.78 GB in 4 minutes 27.315158166999993 seconds
Compressing (packet size 500 ) 63841 files from ./positions to ./compressed_500
Compressing [=====================================================================================================] 100% 63841/63841 111
Compressed 63841 files from 8.97 GB to 4.08 GB in 9 minutes 37.243464958000004 seconds
Tests completed.
50 is definitely the sweet spot for speed - we might be able to optimize further, but time is of the essence. Let's leave it at 50. 500 is way too slow, and we drop from a compression ratio of 5x to about a 2x.
§Round 2 - dedupe
Now we tackle duplication - most of our points are straight up duplicates of each other. We needed more overall points to figure out our packet size, but now's the time to get rid of duplicates:
Something easy to drop are the packets that are too close together in time. Let's set up a simple function to determine if we should drop a packet, based on the last packet.
function dropPacket(previous, current) {
...
const lessThanTimeResolution = MINIMUM_TIMESTAMP_DISTANCE_MS && current.posTimestamp - previous.posTimestamp < MINIMUM_TIMESTAMP_DISTANCE_MS;
...
if(lessThanTimeResolution) return true;
return false;
}
We'll set a minimum timestamp difference of five minutes and see how many we drop:
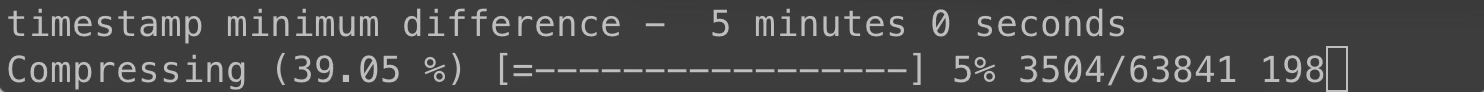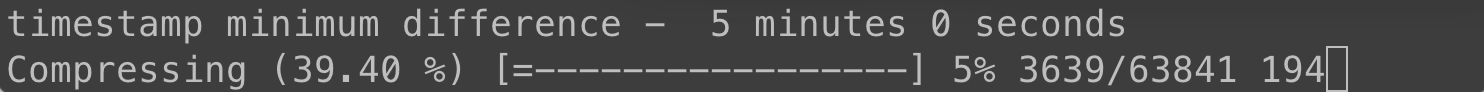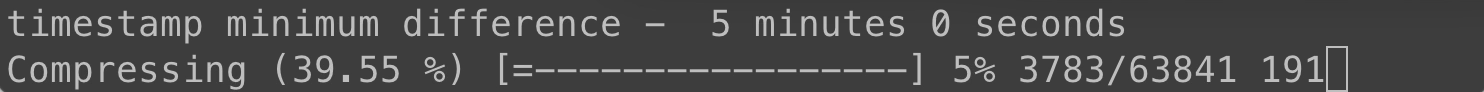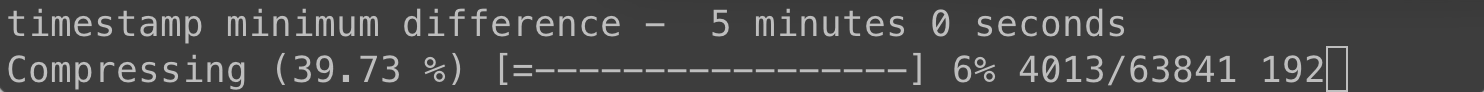
That's almost half! Let's try 15 minutes, which is at the edge of what I would consider acceptable drop in time resolution.
Files - 63841 , Packet size - 50 ,
timestamp minimum difference - 15 minutes 0 seconds
Compressing (66.90 %) [===============] 100% 63841/63841 277
Compressed 63841 files from 8.97 GB to 870.61 MB in 3 minutes 52.251079041 seconds
Passed/dropped 13175056 / 26626572 , drop Ratio 66.90 %
That's now almost a 10x improvement! We have one more dimension we can try the same trick on.
Let's define a geographical resolution for our points below which we drop packet updates. Let's set this to 100 meters, and do a quick Haversine check using our best friend turfjs.
const lessThanGeoResolution = MINIMUM_GEO_DISTANCE_KM && distance([previous.longitude, previous.latitude], [current.longitude, current.latitude], {units: 'kilometers'}) < MINIMUM_GEO_DISTANCE_KM;
Let's disable timestamp resolution and see what we drop:

Thankfully we don't lose much of our speed, and we still drop about 60% of packets, with timestamp resolution disabled.
With these checks in place, there's two ways we can enforce these checks (both of which we'll try). The first is to enforce both resolution limits, to say that we don't log updates unless a vessel moves more than a certain distance, and when the update comes after a certain period of time:
Files - 63841 , Packet size - 50 , Minimum Distance KM - 0.1
AND timestamp minimum difference - 5 minutes 0 seconds
Compressing (71.75 %) [===================] 100% 63841/63841 272
Compressed 63841 files from 8.97 GB to 784.16 MB in 3 minutes 56.550974333 seconds
Passed/dropped 11254408 / 28583441 , drop Ratio 71.75 %
Overall good ratio for drops, for 100 meters or movement and 5 minutes of time resolution.
The second method is to choose not to drop packets when either resolution is hit. So we'll log packets if they come after the time interval, or they come far enough apart:
Files - 63841 , Packet size - 50 , Minimum Distance KM - 0.1
AND timestamp minimum difference - 5 minutes 0 seconds
Compressing (21.41 %) [===================] 100% 63841/63841 236
Compressed 63841 files from 8.97 GB to 1.51 GB in 4 minutes 32.40721566600001 seconds
Passed/dropped 31003007 / 8443749 , drop Ratio 21.41 %
Tests completed.
Significantly worse drop ratio, but the gain is that we can distinguish between the state of a vessel not moving at all while sending position updates, and a vessel not sending any position updates at all. In our and case, the two would be indistinguishable. This affects what we can use the data for. If we were calculating common routes - and therefore only interested in movement - we would go with the much higher compression, whereas if we were trying to look for areas of congestion and lack of movement, we would need the latter.
Let's see if can't relax our resolution a little more:
Files - 63841 , Packet size - 50 , Minimum Distance KM - 0.5
AND timestamp minimum difference - 15 minutes 0 seconds
Compressing (48.13 %) [=======================] 100% 63841/63841 247
Compressed 63841 files from 8.97 GB to 1.12 GB in 4 minutes 20.41667312499999 seconds
Passed/dropped 20568387 / 19085741 , drop Ratio 48.13 %
We seem to be hitting a comfortable middle ground for now with an 8x compression ratio. Let's focus on potentially smaller gains, the first of which is to store our timestamp differences as a delta, instead of complete timestamps. With protobuf having variable length encodings, this should claw back some more space.
Let's start with just a straight up delta value, no additional resolution changes:
Files - 63841 , Packet size - 50 , Minimum Distance KM - 0.5
AND timestamp minimum difference - 15 minutes 0 seconds
Compressing (48.13 %) [=======================] 100% 63841/63841 243
Compressed 63841 files from 8.97 GB to 1.07 GB in 4 minutes 23.716203542000017 seconds
Passed/dropped 20568387 / 19085741 , drop Ratio 48.13 %
Not a huge difference! Maybe it isn't worth the additional complexity. Before we stop, let's try one more trick and enforce our time resolution onto the delta values. We'll maintain our delta values as multiples of the time resolution, see what that does:
Files - 63841 , Packet size - 50 , Minimum Distance KM - 0.5
AND timestamp minimum difference - 15 minutes 0 seconds
Compressing (48.13 %) [=======================] 100% 63841/63841 246
Compressed 63841 files from 8.97 GB to 1019.82 MB in 4 minutes 20.91261700000001 seconds
Passed/dropped 20568387 / 19085741 , drop Ratio 48.13 %
Yup - the 0.8x increase in compression may not be worth the changes we're making. Sometimes you have to climb the wrong tree to see if it was woth barking at.
(Future me: Why didn't we try the same for the distances? Wouldn't it be cheaper to store points as vectors with magnitude multiples of the distance resolution? Probably. Would it take too much time? Probably.)
§Results
To sum up, here are the compression ratios we got for each of our little experiments:
- Binary encoding, packet size of 50 - 5.0x
- 1, plus 15 minutes of time resolution - 10.3x
- 1, plus 5 minutes of time AND 100 meters of distance - 5.9x
- 1, plus 15 minutes of time AND 500 meters of distance - 8x
- 4, plus timestamp deltas - 8.4x
- 3, plus timestamp deltas in units of time resolution - 8.8x
We've largely maintained our throughput of ~ 250 files per second. Once we clean out our code we'll run it on the target server and see what we get.
§Recompression
Now that we've got the general algorithm nailed down, we'll test our system in two ways. The first is to see if we can get into a cycle of recompression with no change to the data. If we're adding anything to the filesize on repeated compression, we have a bug somewhere. If we keep going down in size, we're likely bleeding data through.. a bug! To our system, a compressed file (without additional packets) should be as compressed as possible. Multiple passes shouldn't affect our results.
Compressing once and recompressing, we get:
Files - 63841 , Packet size - 50 , Minimum Distance KM - 1
AND timestamp minimum difference - 15 minutes 0 seconds
Compressing (51.98 %) [====================================================================================] 100% 63841/63841 263
Compressed 63841 files from 8.97 GB to 963.13 MB in 4 minutes 4.120516374999994 seconds
Files - 63841 , Packet size - 50 , Minimum Distance KM - 1
AND timestamp minimum difference - 15 minutes 0 seconds
Compressing (0.00 %) [====================================================================================] 100% 63841/63841 519
Compressed 63841 files from 963.13 MB to 963.13 MB in 2 minutes 4.801075624999996 seconds
We're running through recompression significantly faster, as we should. My gut feeling is that we're filesystem limited (or filesystem library limited) on this one. When I get a chance (in a few months) to do a second pass at this code, I'll likely work on improving recompression speed. I wonder if a single pass to check if any compression is needed will save a whole bunch of reads and writes (narrator: it will).
Running two more rounds of compression on our already twice compressed data, we get:
Files - 63841 , Packet size - 50 , Minimum Distance KM - 1
AND timestamp minimum difference - 15 minutes 0 seconds
Compressing (0.00 %) [====================================================================================] 100% 63841/63841 569
Compressed 63841 files from 963.13 MB to 963.13 MB in 1 minute 53.84621812500001 seconds
Files - 63841 , Packet size - 50 , Minimum Distance KM - 1
AND timestamp minimum difference - 15 minutes 0 seconds
Compressing (0.00 %) [====================================================================================] 100% 63841/63841 568
Compressed 63841 files from 963.13 MB to 963.13 MB in 1 minute 54.271404417 seconds
All good! A quick visual check of the files ensures that we're generating the same data.
Second, we'll try and convert one of our biggest routes (and the compressed version) to GeoJSON, and try plotting them next to each other to see what they look like. I remember working on randomness-generating circuits a long time ago and being told that the best way to tell if something was random was to look at it. The human brain is still the best thing we have for pattern recognition.
We can write up a little part of our code that stuffs any coordinates it sees into a little geoJSON polyline, and take a look at one of our biggest files:
(PS: I'm not mentioning the many, many bugs I'm finding and fixing as I run these tests - we're already running too long. Let's presume either that I made many mistakes, or that I made none, and move on.)
Success!
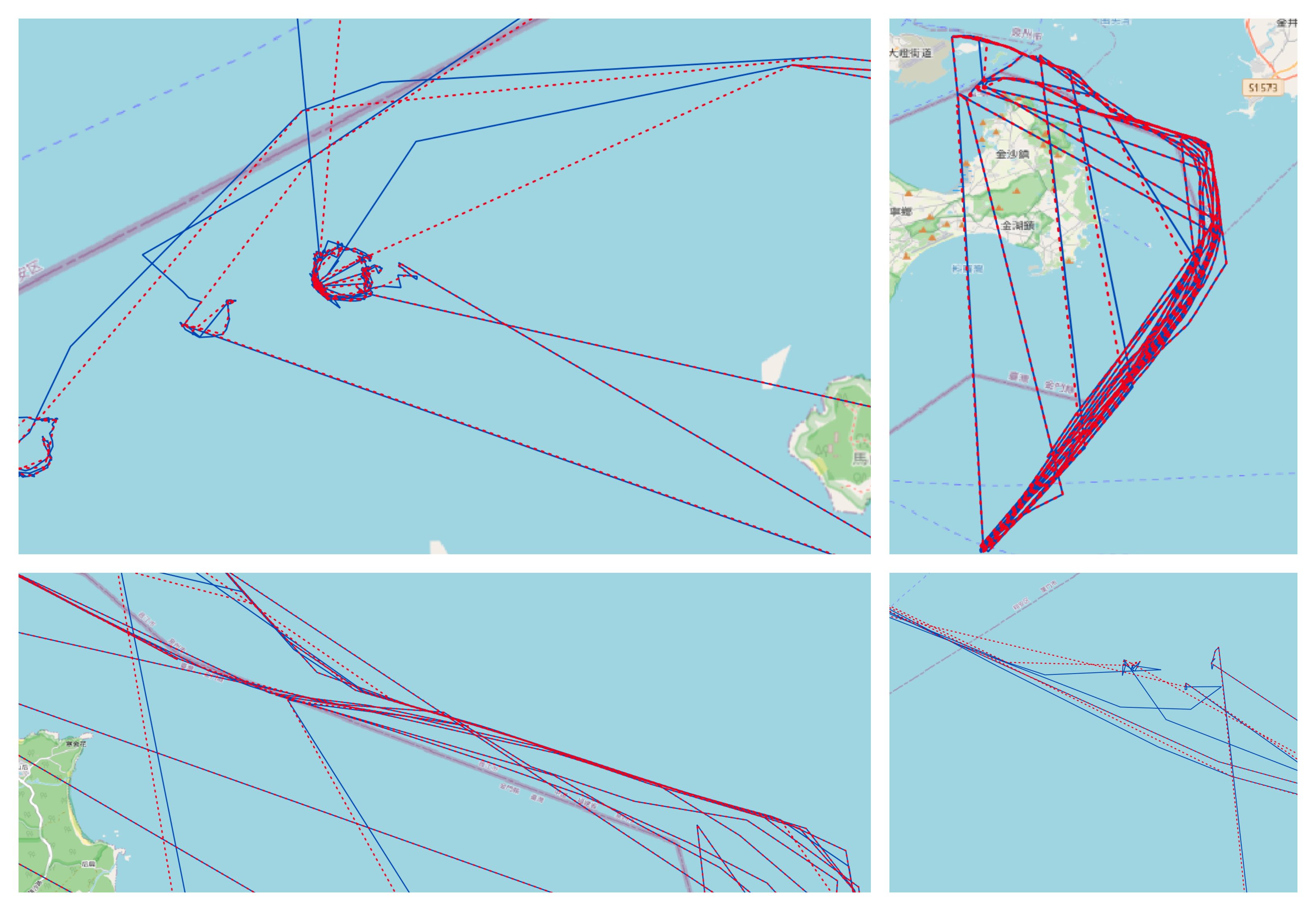
§Runtime compression and testing
Finally, let's run this code on our (significantly smaller) server, and see what speeds we get.
Files - 63841 , Packet size - 50 , Minimum Distance KM - 1
AND timestamp minimum difference - 15 minutes 0 seconds
Compressing (52.57 %) [=========================================================================================] 100% 63841/63841 76
Compressed 63841 files from 8.97 GB to 918.15 MB in 14 minutes 7.57137977299999 seconds
We are definitely slower (about 76 files/second) on the server, but still within acceptable limits.
§If we had time
We'll likely stop here since we are at good-enough levels, and we're T-2 hours out of time. If we did have time, here are a few more things I would have liked to try:
- Implementing deltas for positions - converting the latitudes and longitudes to integers and only storing deltas would likely give us another boost in compression, but we need to do a bit more math to make sure we don't lose geographic resolution here.
- Deciding not to compress - we ideally want to implement a solution to figure out when a file needs to be run through and compressed again. We currently run through any file we have an update for - which is much faster since we don't recompress existing compressed packets - but we would ideally want to leave files alone until they need to be compressed. Something to look into!
§Small things
Running with all of our optimizations and some more hyperparameter tuning, did we get the elusive 10x?
Files - 63841 , Packet size - 50 , Minimum Distance KM - 1
AND timestamp minimum difference - 15 minutes 0 seconds
Compressing (52.57 %) [====================================================================================] 100% 63841/63841 305
Compressed 63841 files from 8.97 GB to 918.15 MB in 3 minutes 30.554461792000012 seconds
Passed/dropped 19692062 / 21821945 , drop Ratio 52.57 %
We did indeed.

Not a newsletter




