Product Lifecycle Lifecycle at Greywing
The lifecycle of software products has always been fascinating to me. Unlike physical goods, software has no definition outside of the problem it's meant to solve. Bananas don't care if you're hungry - they exist regardless. Software on the other hand has no existence prior to and outside of the work its meant to be doing, and can take on endless forms all of which may only be partially correct.
This lack of definition cuts both ways. Done well, this means that software products can tailor themselves to people and issues in ways that other industries often cannot. Done badly, you'll find yourself moving in circles around a good solution, but never quite reaching it.
It is therefore interesting to see how the product development lifecycle evolves around the constraints placed on it by a company - the lifecycle of the product lifecycle, if you will. With Greywing, I've had the fortune of seeing a single example of how things change as you go from inception, proof-of-concept, production, first customer, first employee, to nearing Series A.
Most startups find themselves borrowing and adapting their own solutions to product development in the early parts of their existence. The newer the vertical that is being addressed, the more complicated this problem is to solve - how do you know what needs to be built, how it should be delivered, and when?
Greywing - by attempting to build solutions that have previously never existed in software, within a brick and mortar industry - picked the hardest part of the spectrum. As we've grown from just the two of us in a coffeeshop to multiple teams, customers and feature sets as a company, the process has been pulled and pushed in a number of directions.
I felt that it would be useful to capture this journey in the broad stages we've undergone, and to set down where I expect it will go.
§Phase 1: Teams of one

The first year (or two) of our existence saw us getting to 200K in revenue in the first few months, moving from security marketplaces in Nigeria to risk reporting and then to crewing, with paid customers for each stage of the product.
This is the simplest phase to describe. We had two teams - business and technical. Both teams had a head count of one. Product development often started with ideation on Monday, where my cofounder Nick and I would discuss the meetings of last week, and what new ideas and directions came out of these discussions.
We were simultaneously on the hunt for problems to solve, and to cement whether the problems we were solving were real pain points or nice-to-haves. We looked for areas where capital and time were being spent, where we could capture value by making things more efficient. We presumed that the stronger ideas would surface once we better understood the problem space, while we took our time to build competency and trust in the space by solving smaller problems.
The specific category of small problems I get excited about are the ones that are difficult for a human, but trivial for a computer. One example is an alarm clock - it's near impossible for a human being to wake up at a randomly pre-set time (to the point where a now famous action hero has this superhuman ability), but the same effort is quite trivial for an automated system to make a noise when a counter reaches zero.
Each week saw new problems, which led us to validation. Validation involved mapping out the existing workflow as we understood it, and vetting it with users we found in the wild. It takes a lot of blind men to tell you what an elephant is really like, after all.

Simultaneously, we'd begin sounding out whether this was a solution users would pay for, and what toes existed that we would be stepping on.
As an early stage company with two people, our biggest strength was our cornering velocity - how fast we could deliver prototypes for new solutions, and how quickly we could iterate. This often meant that we would build and deliver solutions within days of finding out a problem existed, and deprecate quickly if it failed to find traction.
Mapping out our process at the time, this is what it might have resembled -
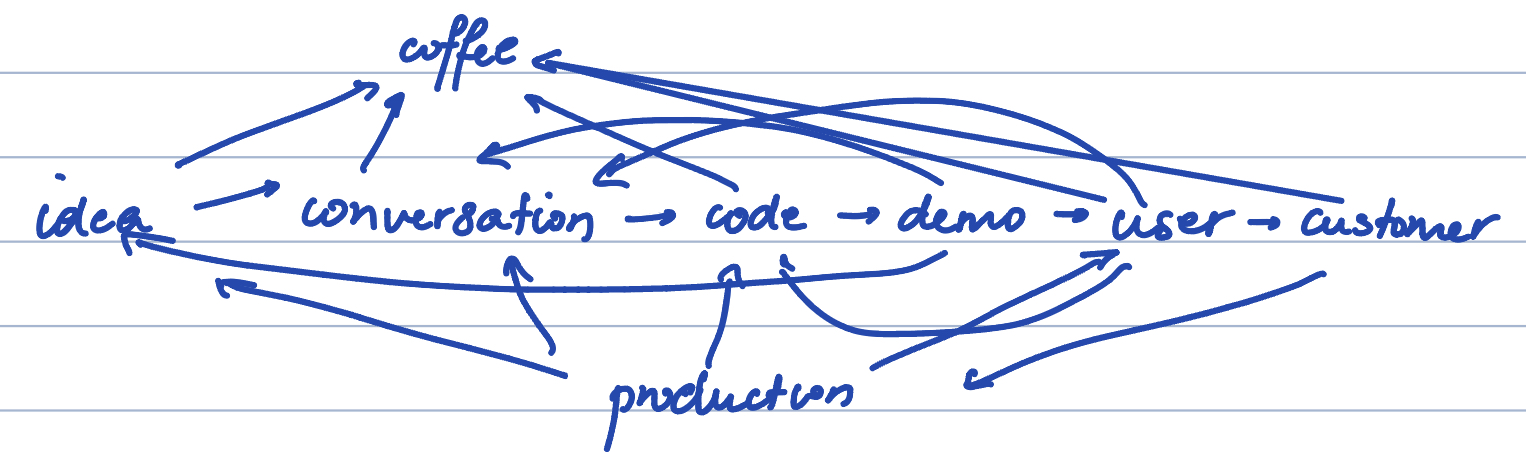
Our product discovery process can be best described as a breadth-first search:
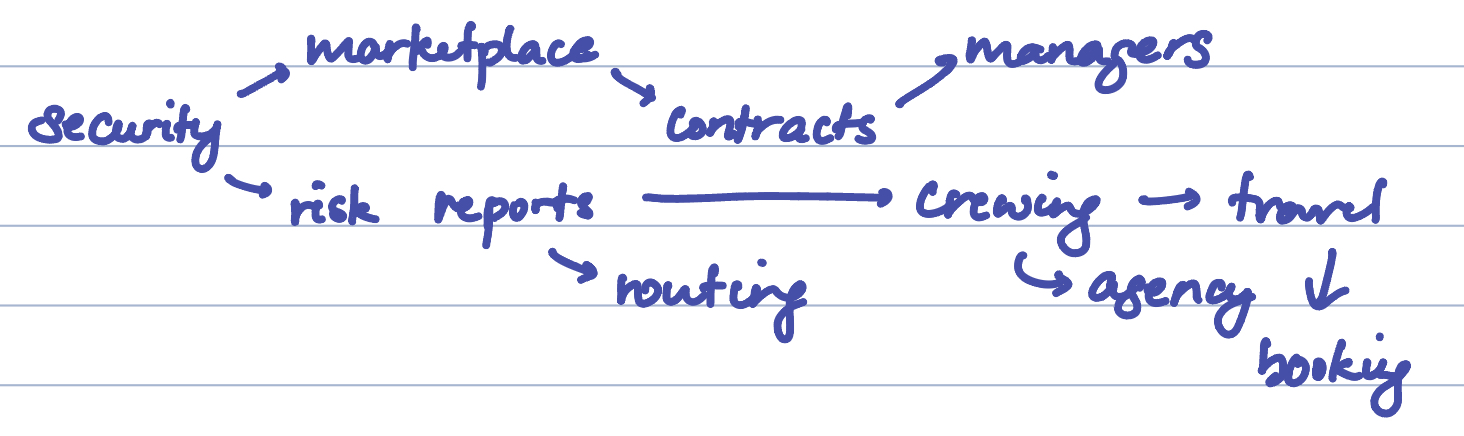
This is what led us down the path to risk reporting, and then on to crewing. Working on security transits, we discovered that risk reports had to be commissioned for each voyage - costing upwards of 1000 EUR per report. Getting our hands on a good number of these reports, we found that we could automate the entirety of these reports at minimal base cost, which led to the whiteboard that formed the basis of CRY4, which still drives a good portion of our current offering:

This phase came to an end with us graduating from Y Combinator, and admitting to ourselves that we needed more hands on deck to handle growth.
§Phase 2: Deeper branches
Once we had good traction with risk reports, the focus shifted into fleshing out the full product. What additional features would users want? How best to build a product and not a proof-of-concept?
This was the time of checklists. Being that the product team was entirely one person, I got into the habit of making multiple checklist boards, archiving them when finished, and calling that a new version. We didn't really lock versions or specs down, given how much new information was coming our way each week.
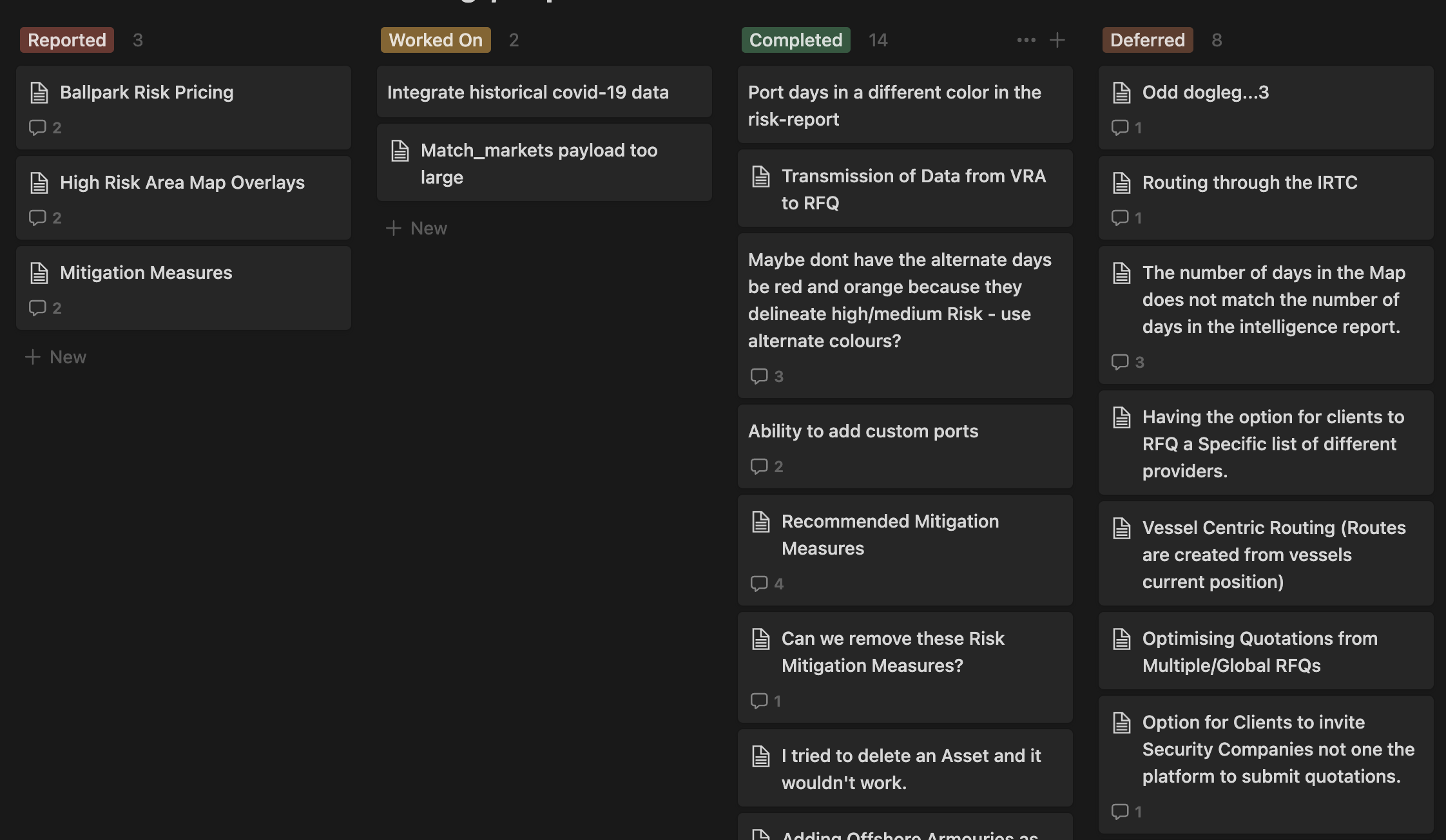
A lot of these features were quality-of-life things that users expect, but don't necessarily tell you about. Things like save buttons, sharing, colors, legends, and more. Once development shifted to these, Nick and I worked largely in siloes where things were run based on instinct. We would regroup once a week (the longest was once in two weeks) to review what had been done, and add comments and new tasks before splitting off again. Some early commits show the general nature of updates:
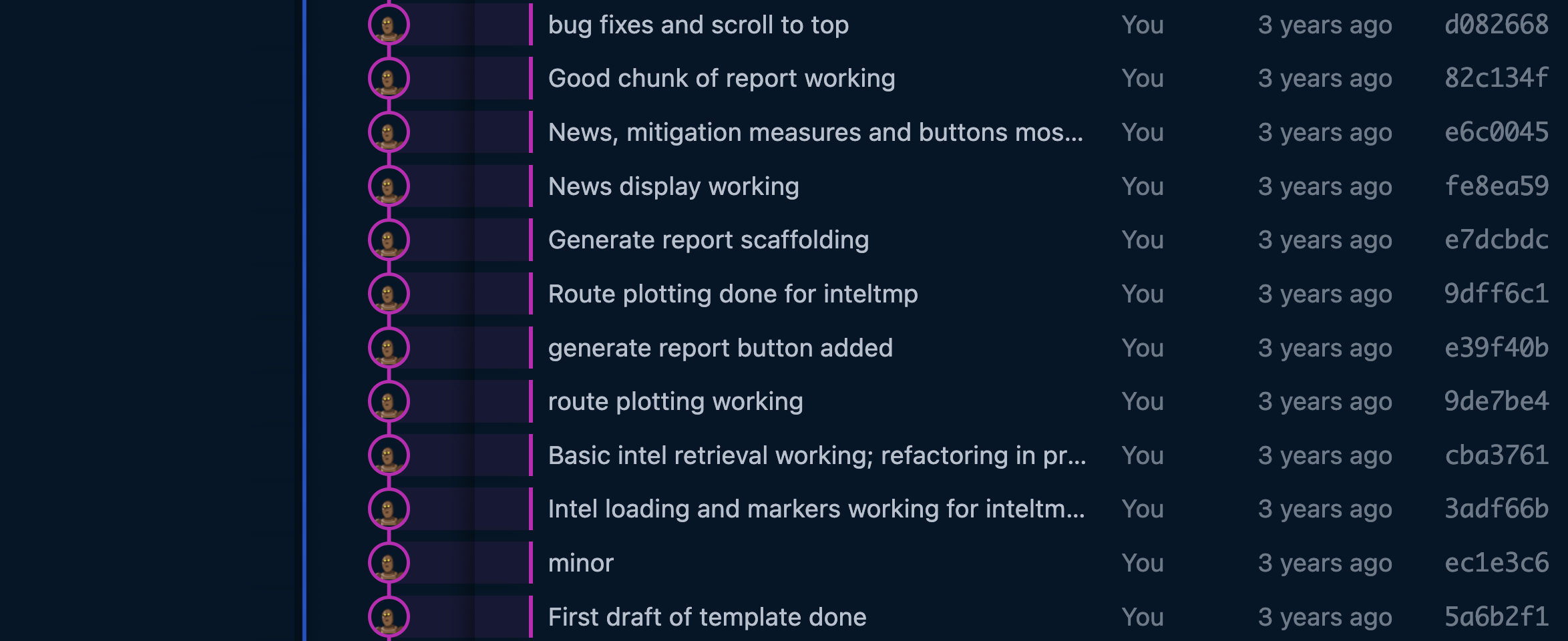
These were exciting times. Everything moves faster when you run on instinct - but it can also be the really, really fun race into a wall for a product and a company. It's always nerve-wracking and painful to put something you've built in front of a user, and it can be easy to get into a mindset where you presume you know the problem and the solution well enough not to need that in your life until the very end.
I'd like to say we put it in front of customers as often as needed, but the retrospective truth is that we should've done more. What we know now, thankfully, is that we at least did it enough to sidestep building things that might have killed us.
There is often no right answer to how user-driven product development should be. Either extreme - too much or too little, is clearly bad. Users are your best source for key answers about how to build your product, but if you ask too many questions, they can also be your worst. All of us want to have an answer - especially when put on the spot - and our brains often come up with things with little thought that make no sense. If you ask someone point-blank whether they want a button or a feature, they'll give you an answer. It's hard to know when that answer should be listened to.
As an example of a dead end, something we built in that time was called Landfall, which was a risk asssessment tool for the Covid Risk onboard a vessel. Landfall looked at the risk levels of prior portcalls of a vessel, and of the nationalities onboard, to produce a risk score that could be used to assess whether a vessel should be allowed to dock and conduct operations. In a world where countries were closing down entirely and seafarers were left stranded at sea for over a year, it was a viable solution - especially for vessels that had been entirely at sea with no instances of covid for six months or longer.
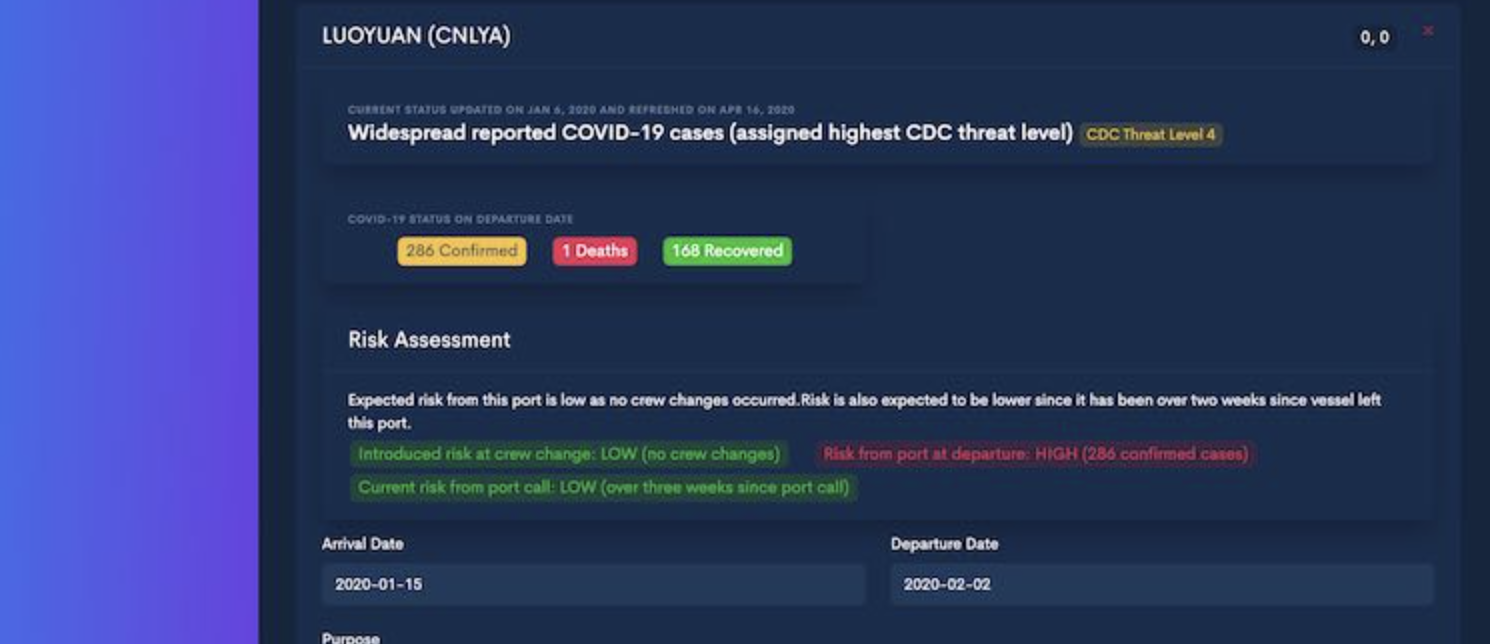
We built it after consultations with port authorities and crewing unions of multiple countries, who were positive they could use it. In the end, we did see some crew mobilization where the tool was useful, but most countries decided to remain completely closed with no exceptions. This was disappointing - both on a product level but also on a human one - and I wonder if we could have seen it coming.
§Phase 3: organisational memory
Pretty soon the overall team had reached (and was quickly growing past) a team size of five. We had two on the business side, and the rest as engineers (including me). Things needed a lot more structure, and the goal became to have as little things in head as possible. We were already using Notion (as you may have noticed from the screenshots) and Mattermost, but we added Monday (which both Nick and I were decidedly against due to the high ad volume we encountered from them, but they were good for the job) and standardised our use of Dropbox and Google Docs.
The biggest issue that comes with a bigger team is information retrieval. Even a company of four generates a veritable hill of documentation, decisions, reasoning and discussions every week. If this isn't well organised ('well' is a relative term), finding things that lie beyond immediate working memory becomes impossible. Why did we make this decision? What materials did we have at this time? The older the subjects of these questions get, the harder it becomes to understand what was happening at the time.
A different reason is the unavoidable fact of team churn. Despite attempts to avoid it, team members (or even cofounders) can leave, and often they take with them what remained in their head and was never put to paper. We've been fortunate in our choice of colleagues that we can always reach out if something critical needs to be remembered, but it's not something we should rely on as first practice.
For these reasons, we agreed on the following rules of thumb for knowing where to put something:
- Mattermost is for quick ephemeral communication. If you're uncomfortable with something being forgotten and irretrievable in a week, move the discussion elsewhere and link it in.
- Notion is for long-form discussions, with our company doc structure deciding where things went. Spec preparation, feasibility studies, user reviews, etc. are to be conducted here and linked in elsewhere.
- Dropbox and Google Docs are for storage. Dropbox is for long-term storage. GDocs is to for collaborative documents, but always to be linked in to a discussion on Notion. We live in perpetual fear of losing things in the ill-maintained and hard to find world of Google Drive. If you find yourself using Google Drive as the main interface, you've gone wrong somewhere.
- Monday is for task specific discussions. If something gets to Monday, it's a specific actionable task, ideally one that can be completed in a week. If it's longer, it should be split into subtasks.
- Github and the pull requests therein are for code-specific discussions about implementation, robustness, and correctness, intended primarily for the dev-team.
We had already been using a Notion template I had created (in expectation of team growth) for some time, and this made things quite a bit easier to manage in specific cases. For example, user directed work started in User Requests, which used a Notion database and templates to answer specific questions that were useful to the product team for picking them up. Notion templates have been essential, as they can easily present fixed questions that make sure nothing important gets missed due to time.
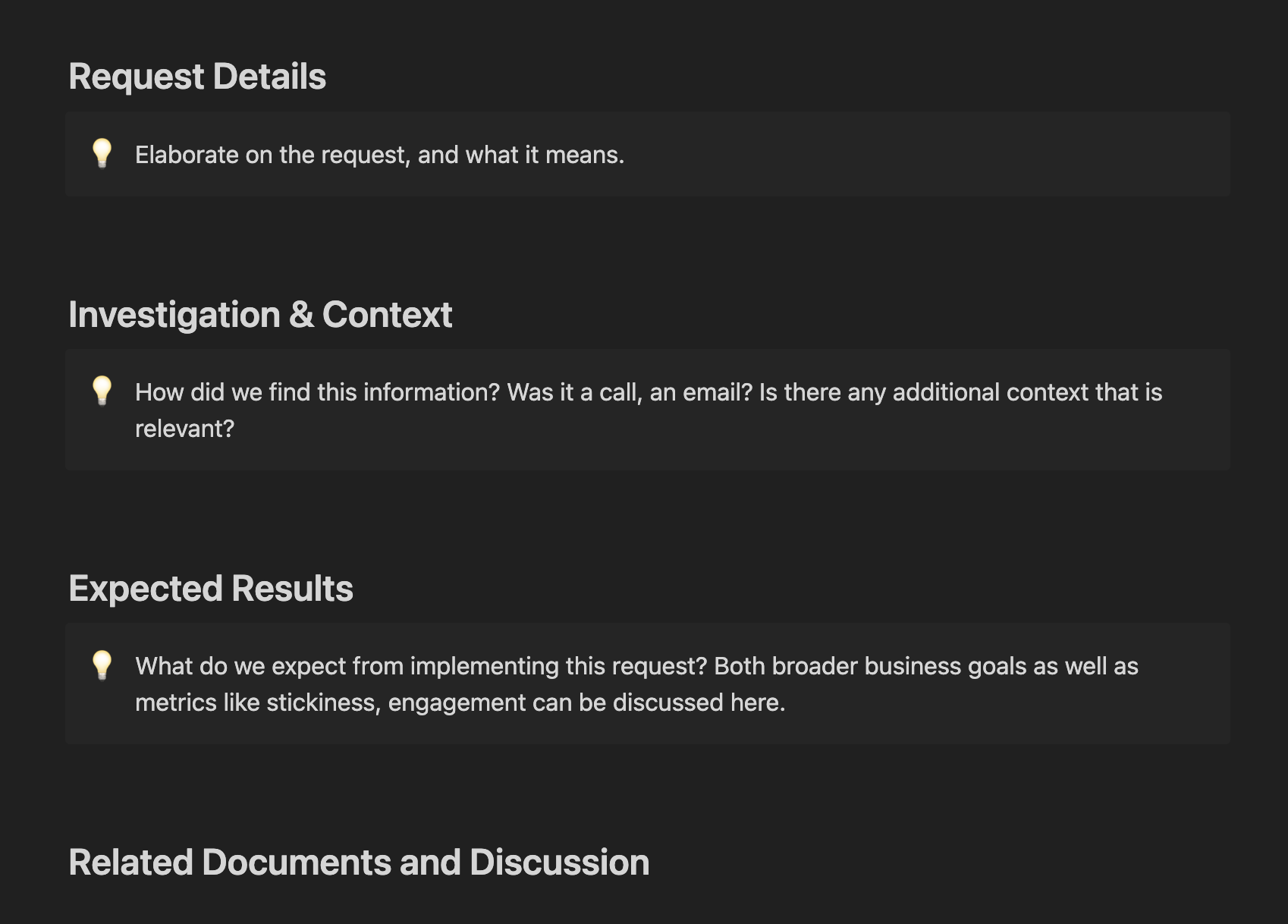
Broader categories were also made, with specific desks (or documents) for each team member where they could manage their day-to-day, and link in others as needed.
§Phase 4: Emergent Pipelining
Once we had this in place, the next step was to put together a more cohesive flow for things. When you're a two person company that hangs out all the time, it's pretty easy to discuss this feature or the next six months of product in between sets during a workout. When more people are involved, information can get lost (too few touchpoints), or meeting loads become unbearable (too many).
My primary goal for the development team was to keep scheduled meetings to a minimum - and to be clear about who needed to be at a meeting and who didn't. Everyone can see the calendar, and is always welcome to sit in - but if you find yourself regularly tuning out a meeting you're invited to, it's a sign you don't need to be there - or you do and you probably shouldn't be tuning out.
With this goal, two scheduled meetings were set up for the entire development team. The first was Sprint Planning on Tuesday, which is laying out the plan for the week, and to review anything that might have spec issues and correcting them. The second is Dev-Chat, which happens on Thursdays and is meant to be a catch-all meeting for anything we didn't have time for that week. Having a general meeting for this purpose significantly shortens most other calls of the week. Anything that goes out of scope in a meeting or needs team input is shifted here - and so far we've had talks, general tech rants, discussions about UX, and a lot more. I find myself looking forward to Thursday in general.
Outside of the development team, here's how the current process works:
§Step 1: New ideas
Ideas often come from three possible sources: suggestions from users, suggestions from sales prospects, and internal jolts of inspiration. The first two (and often the third) go into User Requests on Notion, where they're catalogued and picked up at the weekly Product Meeting on Friday. Insomniac ideas are often brought up ad-hoc at product meetings, and usually sent off for more feasibility and market validation.
At this call, with one representative from business and one from tech, decisions are made on whether this is something to action, how difficult it would be, and when to action it.
§Step 2: Scope of Work
From here, depending on the size of the project, a document on Notion is made to collect discussions, feasibility checks, user comments, etc before things are actioned. This is usually done by me.
Once that's done, we move on to the work.
§Step 3: Actual Work
Here, the project is broken into tasks and assigned individuals, with expected timelines during the short Sprint Planning Planning meeting with our PM, me, and the Head of Engineering.
These tasks are then assigned in consideration to individual load at the Sprint Planning meeting. Most of the task-related discussion happens here, as well as in PRs and Monday threads. We also do some periodic backlog grooming.
§Step 4: Preparation for Release
Functionality releases happen on Wednesday - that is frontend releases, especially since our migration to JAMStack with Netlify. Backend releases happen on Tuesday, and both days have changelogs written out for internal use by their respective team leaders. There's also a brief QA script we follow before release as well as an E2E testing suite that is slowly being built out.
Here's an example changelog:

Immediately post-release, we have another round of testing to uncover any more bugs, which are documented in a Notion doc for each release. Anything unassigned or unclear here leads to a review meeting on Thursday, which is only held if there is something to discuss.
§Step 5: Release
Once the changelog is out, marketing and customer success use screenshots and videos from the changelog to build copy that goes out to sales and the userbase. Here's an example:
One of two things happen after this: bugs, or engaged users for the new things start demanding more, and we're back to User Requests again - making this a cycle.
§Phase 5: Doing better
The goal for my time at Greywing has been - in this regard - to find the right amount of process and to keep updating it, as the team, the company, and the product change. Too much process is a very real problem I've experienced, leading to slower output, and TPS Reports about TPS Reports. On the other hand, too little process often leads to too many meetings, lost information, confusion and stalls.
Our current system leaves a few things to be desired:
- With more people in the loop and a growing user/customer base, knowing about releases ahead of time makes it easier for departments to plan outreach. Some more documentation on what exactly is being built - in a business-friendly way - will make this easier. As features become more complex, adding documentation (walkthrough videos, steps for demo) should lead to faster uptake internally for new releases.
- As the product increases in complexity, the problems we tackle have also increased in Lines-of-Code and our ability to wrangle them. We've noticed a recent increase in specification drift too close to release, leading to last minute work. The challenge now remains in how much more to add to early specifications so that we keep this manageable.
- Temporary team churn - with people taking time off or being unavailable - has increased simply as a proportion of team size. For us, this means having at least four eyes on a problem and to have fewer singular points of failure.
§Conclusion
I hope this has been an interesting journey through one startup's journey in the product lifecycle. The goals that affect us all are the same - faster iteration, stable products, fewer meetings, better communication, etc. However, I've found that each company's path through this forest takes a different turn, often because of the randomness of the world. Our path would have looked different had we been two business-trained cofounders at the beginning with an outsourced team, and even more different had one of our first hires been responsible for product.
I remain unconvinced in the Schopenhauerian idea that this has a path-independent outcome - that all companies will eventually converge on similar solutions - so I hope that explaining our path will help others that tread this way.

Not a newsletter