Subqueries and CTEs: an example of query optimization in Postgres
This post is about some of the problems and considerations we ran into when running substring queries over a large dataset in Postgres, and a demonstration of using the query planner to understand the underlying actions behind each SQL query. Before I go into it, here's a small brief on what we're trying to do. If you already know the story, feel free to skip ahead to The Problem.
We're currently in the process of building a Port Agent outreach tool at Greywing. In short, it's a tool that houses a large database of agents around the world and eases communication between ship managers and agents by automating away the giant pile of email communication that's required any time a vessel considers a port call.
The basic flow goes something like this: you build a growing list of port agents and their emails, whittle it down to just the relevant ones for any user at any time, and perform the communication needed with included vessel and crew information between the agent and the user. In practice, each of those steps is a massive undertaking - if you do it right.
This is one of the times that we've had to break our 80-20 rule when it comes to prototyping products. To do each of those steps somewhat well would take 10% of the time, but it's a lot like the evolution of the eye (or the original problems we had explaining how they evolved). Doing them well enough means a terrible experience for the user, as each step compounds. This leads to lack of use, which leads to a lack of regard for the communication that comes from it, which leads to a vicious cycle. We need to do this well, where the database is comprehensive, the searching is instant, and the communications are polished.
I digress. This is something I can talk about at length (even the UX design has been a massive effort - how do you accommodate power users that need fine control, and users that just want to click a button? Maybe I'll cover that in another post).
The problem we'll address in this post is the query over the Port Agent database. The intention for this query is to allow users to search for port agents based on their Email, Location and Agency associations. In addition, we need to implement access control such that anything in the public database can be searched by anyone, but data from your domain should not leak outside of it.
The desired functionality is an infinitely scrolling search, something we've implemented before with Ports and Airports. Search terms are sent to the server, and the results are paginated for infinite scrolling.
§The Problem
The database currently has >7K rows, and this is only expected to grow. How to do this well? With a relatively simple query, we can perform a substring search on these columns:
SELECT * FROM port_agents WHERE email ilike '%wil%' or region ilike '%wil%' or agency ilike '%wil%';
The problem here is that all the results are in one set, with no way to distinguish which column was matched. There's also no way to order these rows by some priprity based on this column. We would like all matches for the email to be shown first, with additional matches for location and agency to come after. We'd also then like to join them into a single query, so we can use LIMIT and OFFSET to paginate the results as we load them into the frontend.
For better results, we can use subqueries to set a priority field that we order by, like so:
SELECT * FROM (
(SELECT 1 as priority, * FROM port_agents WHERE email ilike '%wil%')
UNION
(SELECT 2 as priority, * FROM port_agents WHERE region ilike '%wil%')
UNION
(SELECT 3 as priority, * FROM port_agents WHERE agency ilike '%wil%')
) agents ORDER BY priority LIMIT 10;
Here's where the first fork in query planning comes in. We also need to show only the agents in the public database combined with the user's domain. We can use a Common Table Expression or CTE to do this (let's call this Query 1), like so:
WITH
visible_port_agents
AS
( SELECT * FROM port_agents WHERE public=true or creator in <user domain>)
SELECT * FROM (
(SELECT 1 as priority, * FROM visible_port_agents WHERE email ilike '%wil%')
UNION
(SELECT 2 as priority, * FROM visible_port_agents WHERE region ilike '%wil%')
UNION
(SELECT 3 as priority, * FROM visible_port_agents WHERE agency ilike '%wil%')
) agents ORDER BY priority LIMIT 10;
The other option (let's call it Query 2) is to bake in the filtering to the subqueries, like so:
SELECT * FROM (
(SELECT 1 as priority, * FROM port_agents WHERE email ilike '%wil%' and
(public=true or creator in <user domain>))
UNION
(SELECT 2 as priority, * FROM port_agents WHERE region ilike '%wil%' and
(public=true or creator in <user domain>) )
UNION
(SELECT 3 as priority, * FROM port_agents WHERE agency ilike '%wil%'
and (public=true or creator in <user domain>) )
) agents ORDER BY priority LIMIT 10;
§Analysis
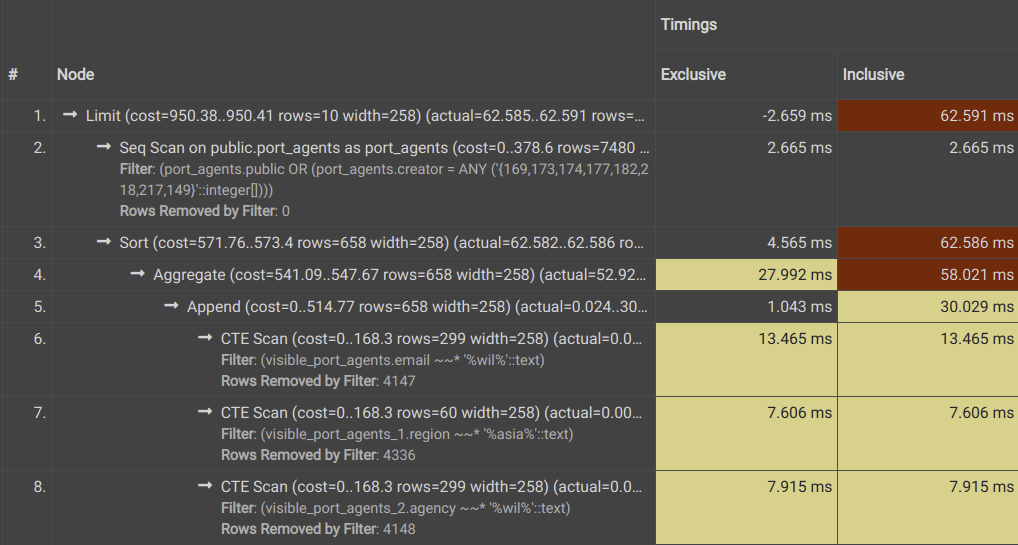
Which is better? Well, since we're using Postgres, we have EXPLAIN ANALYZE to help us. Let's look at the first query, and its execution plan. pgAdmin has a helpful UI for the results, which helps increase readability for what is otherwise a massive wall of text.
A quick look at our query plan for Query 1 highlighted one of the first problems. The scan on the region column was taking disproportionately longer, and this was because we hadn't specified this column as an index.
(Note: This is not always the solution, adding too many indices is a problem in itself. In our case, this is fine as our load on this database is massively read-heavy, and this is the most common query we will perform on it.)
Here's Query 1 (after the fix):
And here's Query 2:

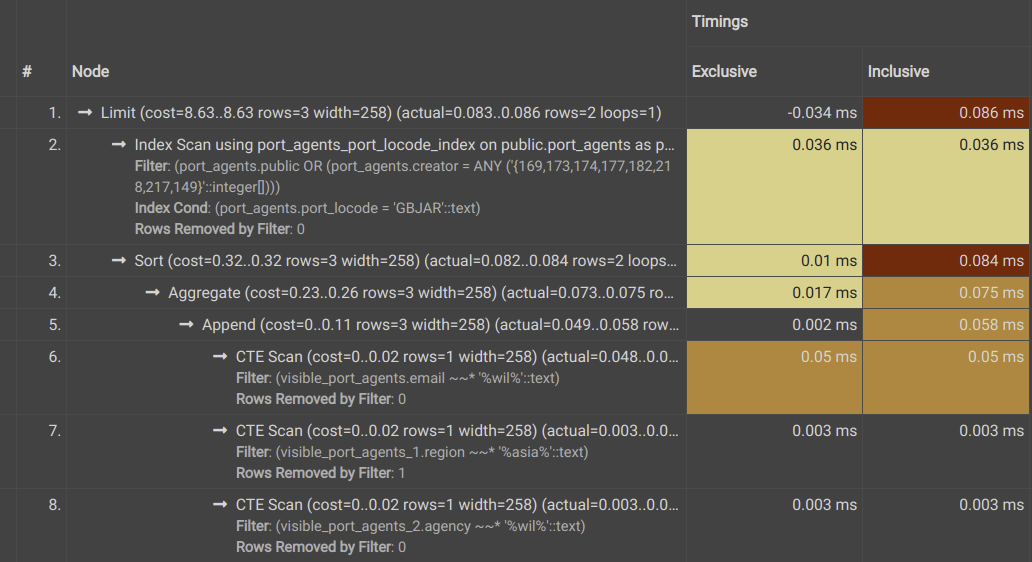
If you're not familiar with Postgres Query planning, here's a small primer: SQL is a declarative language, which (in this case) means that you specify the result you want, not how to get them. When you execute a query, the planner decides what actions to run and in what order, with an estimation of how long each action takes. In the plans above, you'll see that the planner executes a number of Scan, Sort and Aggregate functions to finally get us the results we want. The Exclusive times shown is the time each operation took, and the Inclusive time is the amount of time (in milliseconds) that each action combined with all the actions down the tree took.
The first thing we'll notice is that both of these are massive queries. We're running a substring search, which is an expensive filter. Secondly, we're performing this search on multiple columns before concatenating the result. Beyond a certain size, using systems like ElasticSearch is the right option - but for a feature that we're testing the usage of, complicating the tech stack before validation might be putting the cart ahead of the horse.
Even so, the differences are clear. The subqueries (rows 6,7,8 for Query 1 and 5,6,7 for Query 2) are significantly faster for Query 1 compared to Query 2. This is understandable, since Query 1 is applying these filters to a smaller table - the intermediate table or CTE - while Query 2 is applying each one over the entire table. However, it's worth noting that CTEs can often be a tradeoff between speed and space complexity, as we're essentially creating a copy table that is being used for subsequent filtering operations. It remains to be seen whether this makes it a worse option in our use case, but our estimation is that it will not be - especially considering the additional filters we might need to apply to our CTE that we'll discuss below.
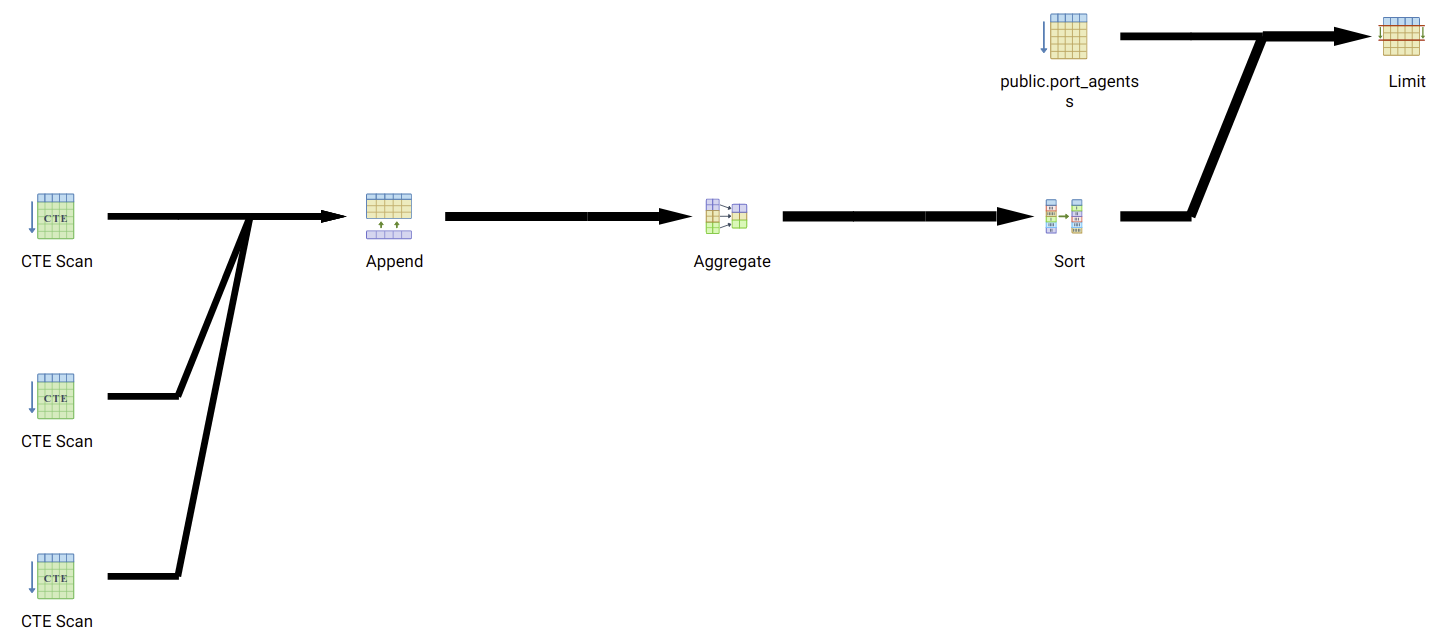
Let's also look at the proposed query plan for both. Here's Query 1:
And here's Query 2, without using CTEs:
Now the aggregate operation (for Ordering) is also quite expensive. However, this is impossible to skip, since filtering ahead of this operation means we lose stability in our pagination.
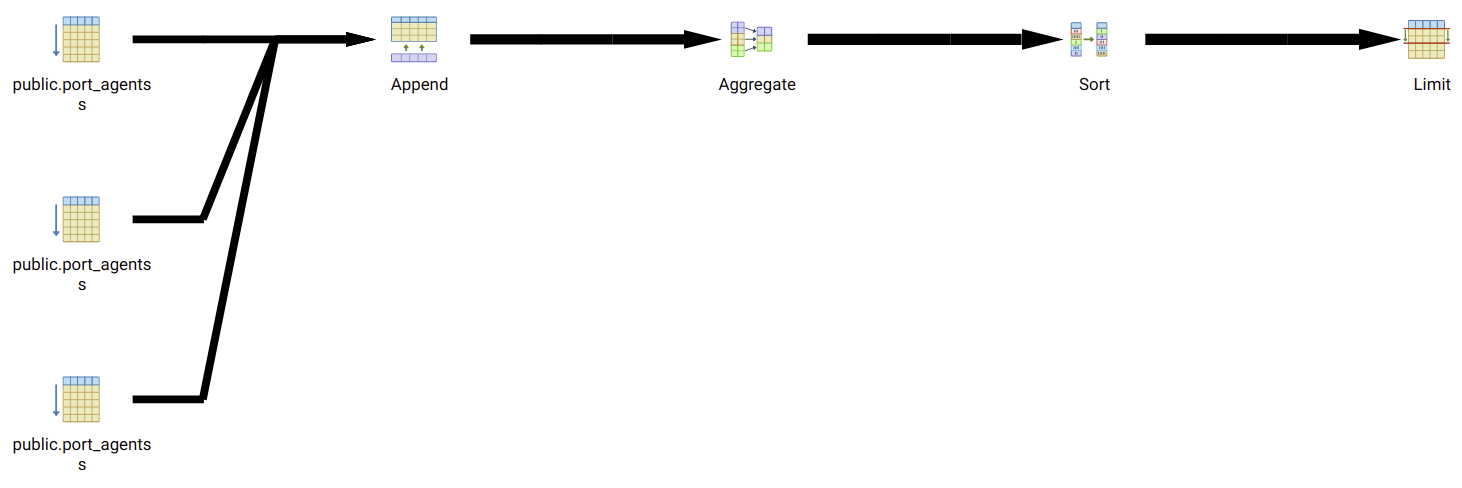
Query 1 is also significantly better as a choice when we add additional filtering into the CTE, as we might do. One of them is to filter for specific ports, to only show relevant agents for each port. This will be ideally built into a switch that users can turn on and off, to look at the global database. This significantly reduces the filtering space for the subqueries, and the margin between the two options. Let's just verify that theory. Here's Query 1 with port filtering:
Here's Query 2:

§Alternatives
There are other solutions that we have used in the past at Greywing. One of them - which we used when performing substring queries on the much larger Ports database - is to have a separate field (that aggregates all the requisite fields) as a query field. For example, the port of Paris, with a LOCODE of FRPRS will have the identifier 'Paris (FRPRS)', which serves the dual function of the display name and the search column. However, the same requirements that prevent us from using a combined WHERE clause (the need for priority) apply here.
An additional point of optimization is with the page size in returned results. Some of the other open searches have been done with a page size of 10, but we've since decided to increase this to 50 due to the relative expense of running this query. Sending about 50 matches is a lot lighter than running this query 5 times. Optimizing for this parameter means making sure that the user selects or rejects this list within the first one or two pages. Any more than that, and we're spending the user's time and our CPU hours showing pages they probably won't need.
§Conclusion
The lesson here (that I've had to learn through some tumbles) is that the query planner is your friend - when writing complex queries (or honestly anything that's not ultra-light), make sure to take a little time and understand how you get the ones and zeroes out of your database.
Also, this is very probably not the best solution to this problem, even within the domain and search space we're working with. This is just me illustrating the choices I could think of at the time, and how I chose one over the other. If there are any suggestions, comments or criticism, I'd love to hear about it!

Not a newsletter