Workhorse models and racehorse models
If you're actually deploying LLMs, it gets hard to keep up with new releases. In the past few weeks alone, we've had:
- llama-405b starts ranking next to GPT-4 while being open source
- llama-3.1 8b becomes one of the best mid-size Small Language Models (SLMs)
- Codestral-mamba becomes one of the best Mamba models out there
- Deepseek-v2 released and people tell me its awesome
- Gemini-1.5 Pro takes first place on the lmsys leaderboard
- Gemma-2b released
and I haven't even covered everything. Having tested over a hundred models (and deployed at least 30 different ones to prod), here's how I've structured thinking about new models and helping them find a home. This has been a helpful rubric for me and folks I know (as well as some cloud providers where I've had to use this metric to explain why I won't use their new model).
§Workhorse or Racehorse?
When a model first releases, the question I have is whether it's going to be a workhorse or a racehorse in my system. Thankfully this distinction is shrinking, but you still have two classes of models:
- Racehorses are expensive, slower, but can do high-level reasoning, complex problem solving, and wear many hats. Racehorses are what you want in your agentic systems using hundreds of tools, or to build quick prototypes when you don't want to spend your time prompting or optimizing. They also get tired if you use them too much (cough ratelimits cough).
- Workhorses are task-oriented, and fit into their specific slot (which you'll need to take time to define and optimize for). Once you do, they are fast and cheap and can happily scale.
Claude Opus is a racehorse (at $15 per million tokens). Gemma-2B is a workhorse at only 2GB of VRAM. GPt 4o-mini is a workhorse at $0.15 per million tokens.
Claude 3.5 Sonnet is my favorite racehorse. Haiku is still my favorite workhorse.
Workhorses and racehorses are governed by very, very different metrics. I'll explain why.
§Racehorses
Racehorse models are models you should rarely finetune - because the segment is one of the most contested in all of AI. The smartest model changes quick and often - plus they tend to be expensive (or unavailable) for finetuning.
Racehorses are defined by raw horsepower - these are the models you pull out when you want to push your systems to the limit. Do you have completely undefined data? Did you just sign a new customer for your system that does not care about cost? Do you want to show off in a demo? Pull out the racehorse.
However, there are very few production tasks that really need a racehorse. Once you're past the demo stage, you should start looking for workhorses - smaller, cheaper, faster models that you can finetune, (ideally own and) modify, and will change less over time.
The exceptions are things like large-scale tool-usage (which isn't something you need often if you figure out dynamic tool management early), real-time UI/code writing, looping or other agentic behaviors.
A common pattern I fall into is using a racehorse model as the main controller in a large system, while using workhorses for things like style adjustment, summarisation, etc.
§Workhorses

I know that's a car - but the analogy still works, and I found the image after I wrote the article.
Workhorses are the reliable part of your stable of models. They're the ones you grow fond of because they're really good at something and they do it without complaint. For example:
- Haiku is an insanely cheap way to do multi-modal structure extraction
- Gemini Flash can do needle-in-a-haystack retrieval above 1M tokens
- Gemma 2b is insanely good for its size and can do writing, summarization and other language tasks on-device
- Hosted Mistral has some of the lowest time-to-first-token speeds outside of Groq
- GPT 4o-mini has great rate-limits
Workhorses usually have two things in common. One - they're cheap (cost per token), fast (TTFT or TPS) or scalable (rate-limits) - ideally all three. Two - they have caveats outside of specific use-cases.
- Haiku doesn't have a proper JSON mode or constrained schemas.
- Gemini Flash has poor rate limits and bad DX.
- You need to run Gemma 2B client-side, and the support isn't fully there.
- Small Mistral isn't great at most coding tasks or reasoning.
- 4o-mini doesn't support prefix completions, which means you can't do reliable continuations.
Any good system you take to production shouldn't be built entirely on racehorses. Take the time to find your workhorses and start relying on them.
These days I have a simple flowchart to decide when and how to use a model.
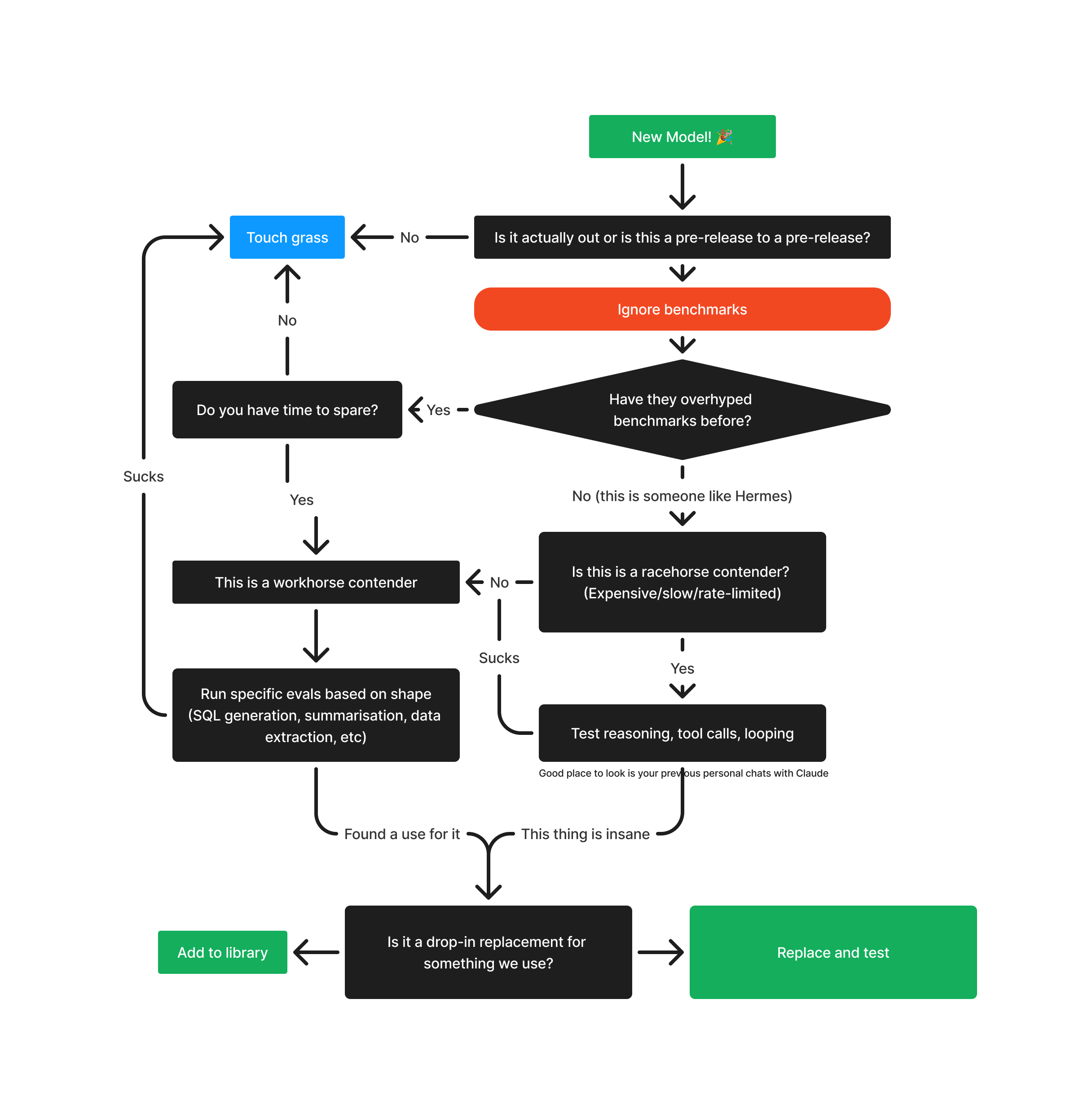
Here's an example of specific tests you might run on a model. Here's another fun test I now run on all models:
It's useful to test every model you can - there's no real substitute to building an intuition for how models work at different sizes, how different architectures (like Mamba vs Transformer) differ, how much style and RLHF can and can't change, among other things. Test finetunes if you can from Huggingface - almost every open source model I've used properly was a finetune of some base model.
§Acknowledgements
I stole this analogy from Murakami's What I talk about when I talk about running, where he describes himself as a workhorse.

Not a newsletter





