Learning to unyieldingly compromise
Security and convenience are at opposite ends of the same spectrum. It's easier not to lock your door when you leave your house - no key to lose, no lock to malfunction between you and your home. Humans are strange. Combine the fact that we hate inconvenience with a passion, and that we find it quite hard to fold in large, uneventful eventualities - something I know dearly from my time in insurance - and we have a recipe for an insecure world at large. Cue post-it notes with passwords stuck to monitors and deliberate backdoors built into secure systems for forgetful users. It's inconvenient to be secure.
This is not to say that things haven't gotten better. Despite their problems, secure enclaves and biometric security have made it significantly easier for software to be secured without slowing down users too much. When I tap the fingerprint sensor on my phone to login to my bank, a secure enclave in my phone's processor is accessing and comparing my fingerprint before unlocking/decrypting what I'm trying to get to.
Things are still far from perfect. They become significantly worse in the cross platform world we build our software in. Here is a brief look into the lines we've had to draw between security and convenience, and where we plan to go in the future.
§Can't lose what you don't know
The fundamental component of end-to-end encryption is that information isn't accessible in plaintext anywhere but either side - the sender of the information and the intended recipient. No service provider in the middle has access to the unencrypted information, which means they can't lose it. If we mark all the segments that only have encrypted data (without the keys present) in green, we should see an unbroken green section covering everything except the origin and the destination.
This protection goes both ways. If your service provider can prove they had no way to access unencrypted data, they can remove themselves from consideration as a potential point of failure and legal ramifications therein. That said, this is really hard, and really hard to do properly.
§Why the edges suck
Let's look at both extreme solution points. The simplest and easiest solution for the customer and the provider is to store all information in plaintext, all the time - unlocked house. Information is easy to access, easy to query, and easy to serve. Low complexity also means lower probability of bugs, easier maintenance for code, and better performance.
The other side would be pretty close to a one-time pad. The user creates a truly random key on an airgapped device, writes down and transfers the it to the device of use, encrypts their information using a software they have independently vetted, and sends the encrypted data to the provider. The service provider dutifully delivers this blob of entropy to the intended recipient, who receives the key from the sender through a private meetup where it is spoken to the recipient who writes it down. With the key in hand, the recipient can decrypt the information.
It's clear that we want to live in neither world, even though there are people and programs that live on either side. How do we find a better solution that works well enough?
§Less of one, more of the other
A number of compromises have been found that offer less security and more convenience. The goal is to be easy enough to use while being secure enough to trust.
One example is passwords. We know that passwords are definitely less secure than full 64/256-bit randomly generated keys, but they're actually possible to remember. Less secure, more convenient.
Another (bad) example is password requirements like four alphanumeric characters, with three heiroglyphs, at least one number. These are usually in use so you don't just type in 'password' - but they also ensure you pick a password that you'll definitely forget. Less secure (if you forget it), less convenient.
Something else that is common are root passwords that are known to the service provider, or workarounds to the main encryption. The main purpose here is to let users reset their passwords without losing their data. Unfortunately, piercing the armor of a secure E2E pipe means that anyone who could use that hole is now suspect. If we count them as malicious (or inept), our data is still compromised. However, an end-of-the-world password reset mechanism is easier to monitor and enforce audit logs on, perhaps through a third party. I have also never seen a user be happy when you tell them that their data is truly gone - because 'your keys, your data'. Less secure, more convenient to have a way to reset things.
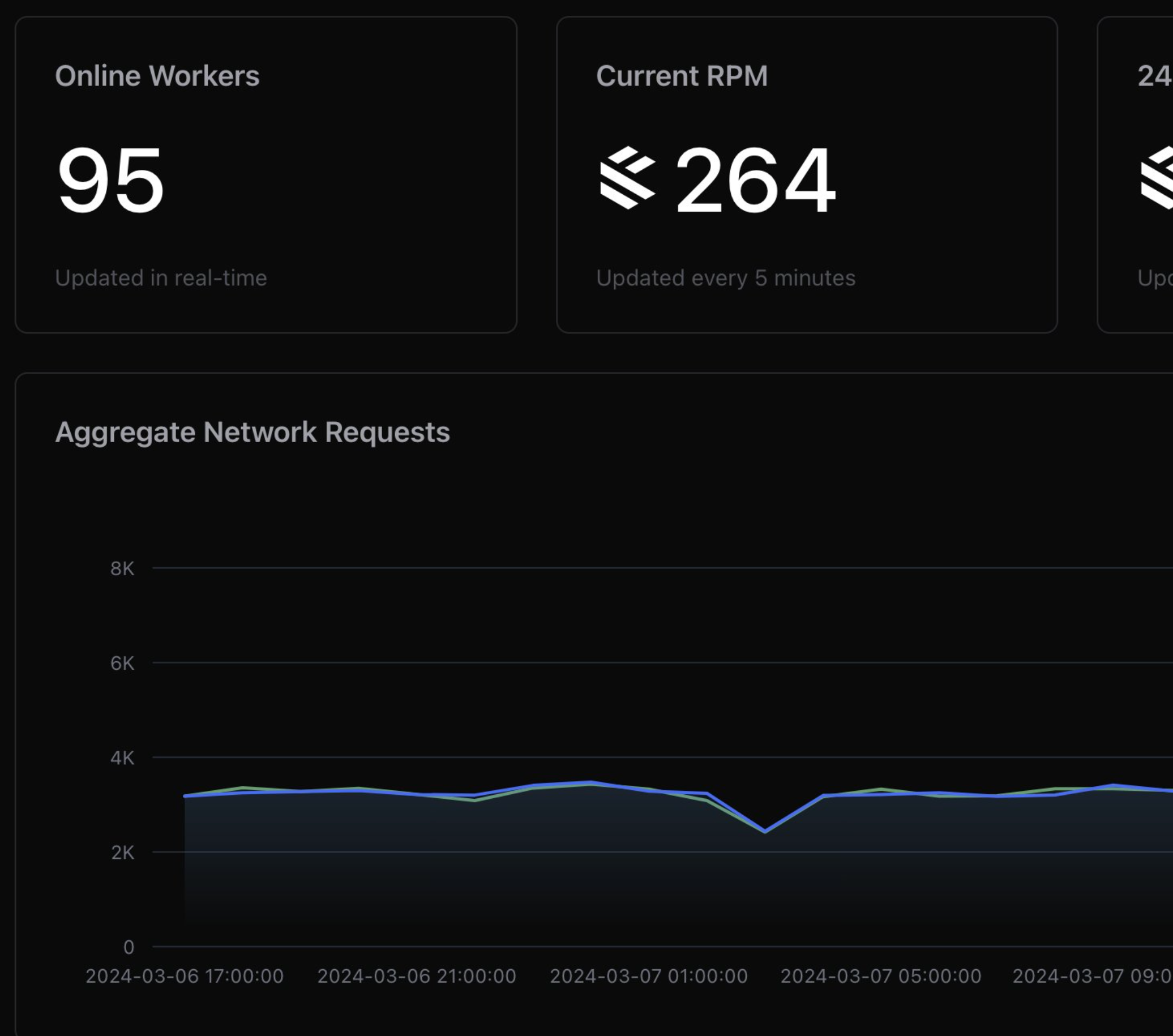
Signal (and now Whatsapp's) key exchange and double ratchet algorithm is a good example of a secure protocol with holes punched into it to improve convenience at the cost of security. The original double ratchet system is incredibly secure, with perfect forward secrecy. The original paper from Whatsapp (linked above) and Signal both reference private keys that are securely generated and exchanged. In practice, users don't want to lose their messages because they've lost their phone - so we add a backup key vault with a password.
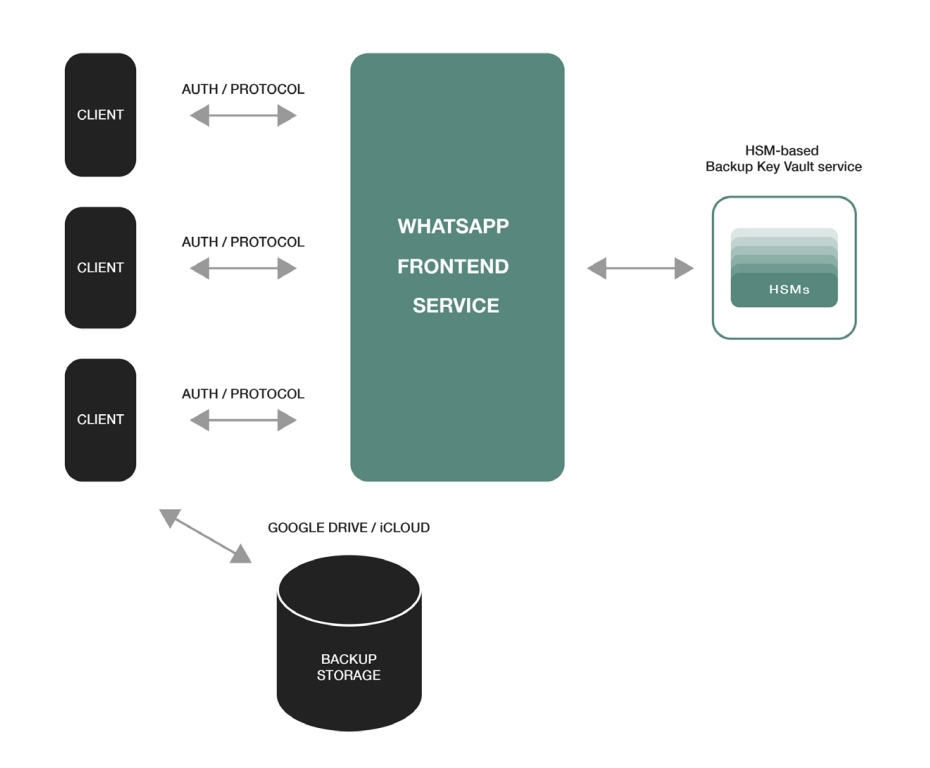
Users don't want to remember a password? We authenticate them via a phone number and retrieve the key ourselves. If we decided we didn't need this verification because we sold ourselves to a billionaire, we get to retrieve all the keys. A lot more usable, but a lot less safe. It doesn't matter if you have the most secure system in the world if it fails to sell, onboard and convert.

§The first of many steps
At Greywing, our priority is to put a system in place that increases security without adding too much inconvenience to the UX, while being extensible that it can be used to secure more things in the future. We also want to define a roadmap for how we can improve security and convenience, given more time and understanding of the problem space.
Here's our example: A user would like to retrieve stored ID cards from our system (which may have come from elsewhere) and email them somewhere.
Simple enough - how do we secure it?
§Armoured carrier pigeons
The first thing we can do is to implement transport encryption (something we enjoy every day with HTTPS and TLS) in a way that doesn't break electronic-goddamn-mail. Email is a very special beast, and email clients often attempt to discard (or flag) encrypted pieces because they can't look inside. You know, to verify that nothing is wrong. Do we see the problem?
To solve this, we have to go to encrypted zips (using ZipCrypto or AES)- one of the oldest file storage formats in use today, which will have the most support across all platforms. Once we do, things are pretty simple: we download the plaintext ID cards directly to the user's machine, ask them for a password, encrypt the files into a zip, upload this as an attachment to our email. The user can communicate this password (which the server never sees) with their recipient through another channel. Secure enough, simple enough. If they forget the password, they can always send another email. Android, iOS, MacOS and Windows have native support for encrypted zips. The receiver can simply click on the zip and be asked for a password, without any knowledge of encryption software.
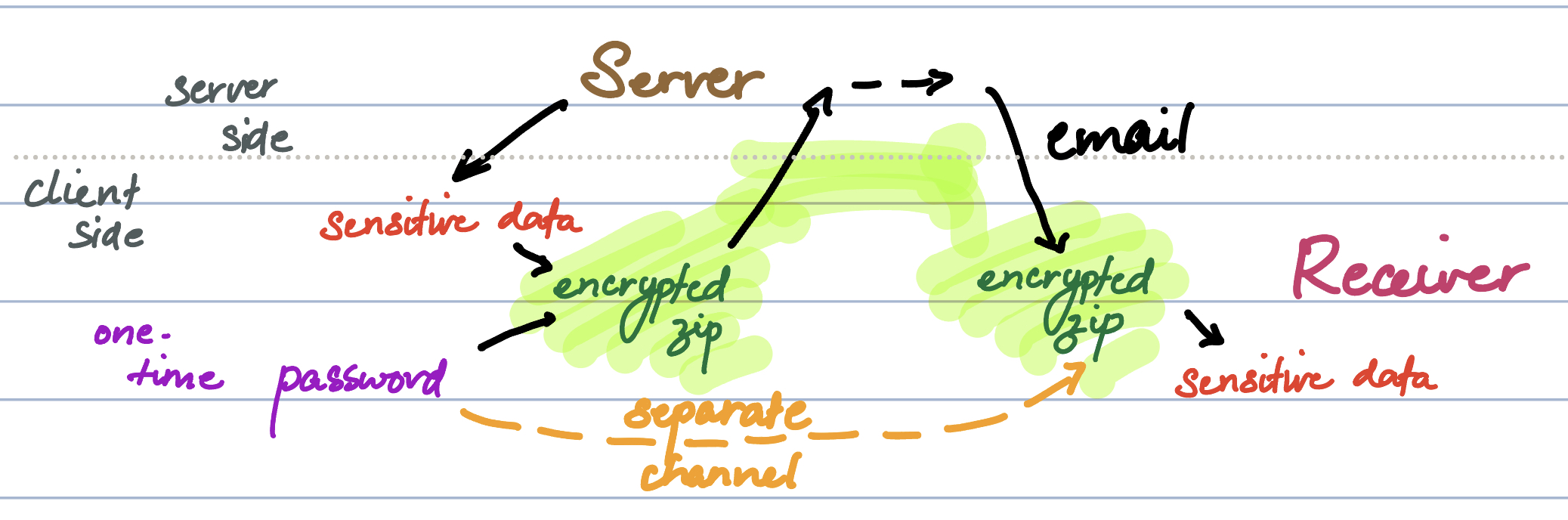
Why isn't it as secure as it can be? Because once it's sent, there is no way to rotate keys or revoke access. We also don't have an access log. It might be more secure in the future to upload the encrypted file to a location we control - like our servers or S3 - and share an expiring link instead. This would be a good upgrade to make once we know that the encrypted zips actually work in our domain.
However, we've already made things more secure than the default (uploading plaintext ids). We no longer have to fully trust our email provider (or any providers in between). We also have a section of green (after the file is encrypted) where our code paths can have lower security guarantees and audits because they don't work with plaintext sensitive information. Now we can focus on extending the green as fas as possible.
§Safe at rest
What we'd like is for the data to be encrypted at rest. If we don't need to know it, we don't need to know the keys. Here's how we can build a system that works, iteratively:
At account creation, let's have the user create a public/private key pair securely on his machine. He can download the private key, and we'll keep the public key. When any information is synced, we encrypt it with the public key and lock it out of our use. The public key can only encrypt, and the private key can only decrypt - the former is with the user and us, and the latter is only with the user. When he needs access, we give him the encrypted file, he decrypts it with his key, applies the email encryption and transport password, and reuploads the newly encrypted file.
This sounds good in theory - but none of our users want to carry around a super-important, human-unreadable file. What if we use a password? All right - we can encrypt the private key with the password, and send it to our servers. Less secure, more convenient. This way, users only have to remember the password. When they need it, we will send them the encrypted key so they can decrypt it on their device. It's never transmitted to the server in a format we can use.
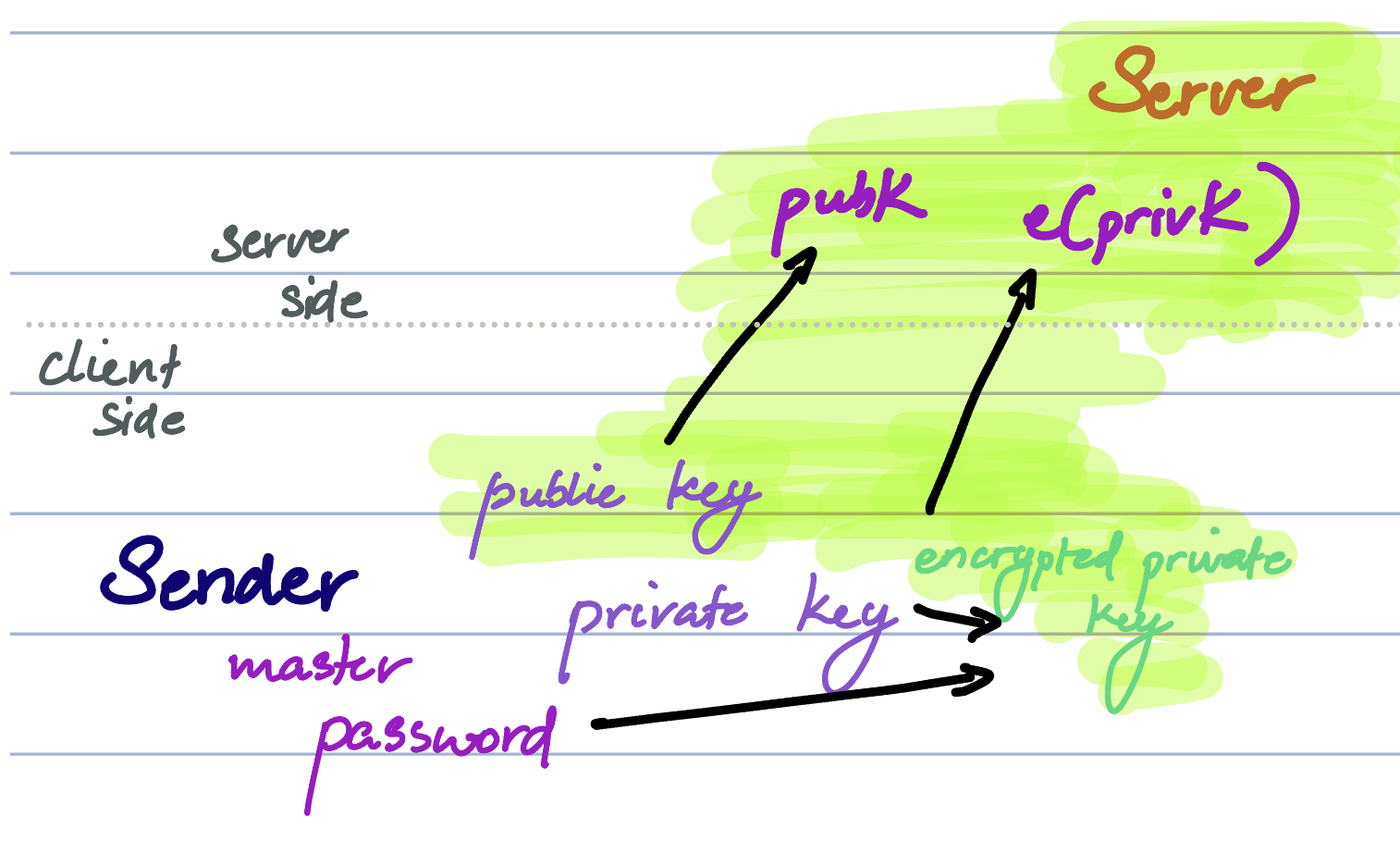
What if users lose their password? We might need to start all over again. One solution is to have a root-of-trust style onboarding process, where we one person uses his password to authenticate/decrypt a master key, which allows a new user to re-encrypt it with their password. If that was too complicated, no worries - we decided it was too complicated from a workflow perspective to be used.
The much less secure, but more convenient version we are starting with is to have a single password/encryption key pair per department. We can add a backup key pair, with a password known to far fewer people in the company. Less secure, but far more convenient.
The overall workflow from the user's perspective becomes:
You request a file, and are asked for the master/department password. You enter this password, and can now verify that the files are correct. Next you need to enter a transport password, after which the email is sent. You communicate the transport password to the recipient, and they can open the file.
Putting our two systems together, we get to see the entire system internally:
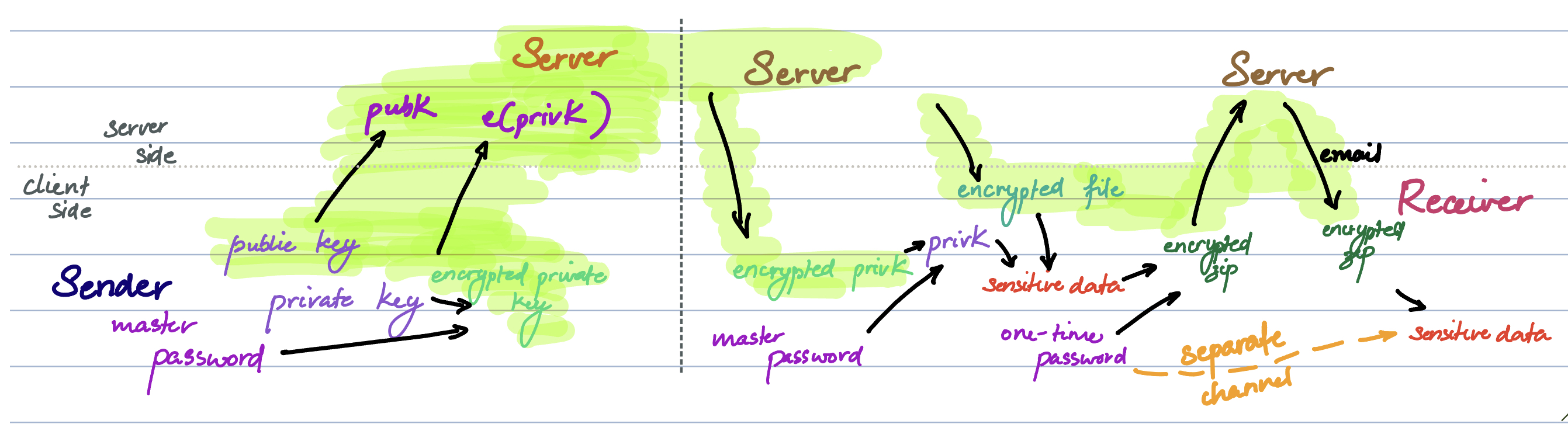
When a user account is set up, a public/private key pair is generated. The private key is encrypted client-side and sent to the server, along with the public key. The password is not known to the server. When a file is synced, it is encrypted with the public key and stored securely.
When it is retrieved, it is sent along with the encrypted private key. The user can input a valid password to decrypt the key, which decrypts the file. At this point, transport encryption is applied to the file and passed on to email processing.
We can see that the server does not handle plaintext information. This makes reasoning about the security of storage, transport, and our codebase much easier.
§Improvements
This is the system we're currently in the process of deploying. Further improvements can be made on this system, both from usability and security standpoints. Once this system has been operational for a while, we might introduce:
- Secure vault encryption with biometric authentication: This would need us to natively support phones, but it's something that would make authentication and key retrieval much easier.
- Secure file storage: I'm not fully aware of the landscape of offerings in this space, but it might also be something we can offer ourselves.
- Column encryption: One big advantage of having this system is the availability of a public key, which is a widely supported method of encryption. This way, we can enable encryption of sensitive columns in our database, or if a client were so inclined - the entire database.
§A treat - if you're a maritime CEO
Courtest of GPT-4, here's a summary of this article explained using maritime analogies!
Imagine your shipping company as a vast fleet of ships, each carrying a cargo of data. Your ships need to transport this data from one port to another, but the size of the cargo and the way it's packed can significantly impact the speed, efficiency, and overall performance of your fleet.
In this article, the author proposes ways to optimize the cargo (data) so that it can be transported more efficiently. The current method of packing the cargo (using JSON or XML formats) is like using bulky, oddly-shaped containers that take up a lot of space and slow down your ships. The author suggests that we replace these containers with a sleeker, more compact design (Protocol Buffers) to make better use of available space and enable your ships to move faster.
The author also highlights that your fleet needs to have a better communication system, like a lighthouse, to guide your ships safely through the foggy seas of data. They recommend using gRPC as this lighthouse, a modern, high-performance communication protocol that allows ships (services) to communicate with each other more effectively.
By implementing these solutions, your shipping company (software system) will be able to move cargo (data) more efficiently, streamline communication, and improve overall performance. These changes will ultimately give you a competitive edge in the maritime industry (software development).
(Yeah, it hallucinated the bit about gRPC - still fun!)

Not a newsletter